
Perché non tutte le GPU possono essere collocate nel datacenter?
L'approccio centralizzato all'architettura IT è sempre stato il modo più comune per affrontare i problemi relativi a scalabilità, gestione e ambiente. Gli scenari di utilizzo per questo metodo non mancano:
- I datacenter che ospitano l'hardware sono molto grandi
- C'è quasi sempre altro spazio per aggiungere nodi o hardware, tutti gestibili in locale (a volte anche nella stessa sottorete)
- Alimentazione, raffreddamento e connettività sono costanti e ridondanti
Quindi, perché dovremmo sostituire un approccio che funziona? Il problema è che le soluzioni universali raramente soddisfano tutte le esigenze. Diamo un'occhiata a un esempio che riguarda il controllo qualità nel settore manifatturiero.
Controllo qualità nel settore manifatturiero
Una fabbrica o una catena di assemblaggio può avere centinaia, a volte migliaia, di aree in cui vengono eseguite attività specifiche sulle linee di assemblaggio. In un modello tradizionale, ogni passaggio digitale o strumento reale deve non solo eseguire l'attività a cui è preposto, ma anche trasmettere il risultato a un'applicazione centrale in un cloud remoto. È possibile che gli utenti abbiano alcuni dubbi su questo processo, ad esempio rispetto a:
- Velocità: quanto tempo si impiega per acquisire una foto, caricarla su un cloud, analizzarla dall'applicazione centrale, inviare una risposta e intraprendere un'azione? Bisogna lavorare lentamente e ridurre il fatturato oppure in modo rapido, con un maggiore rischio di errori o incidenti? Le decisioni vengono prese in tempo reale (o quasi)?
- Quantità: quanta larghezza di banda di rete è necessaria affinché ogni singolo sensore carichi o scarichi costantemente un flusso di dati non strutturati? È possibile raggiungere questo risultato? Il costo è eccessivo?
- Affidabilità: cosa succede se si verifica un calo della connettività di rete? Si ferma l'intera fabbrica?
- Scalabilità: partendo dal presupposto che gli affari vadano bene, un datacenter centrale è in grado di gestire tutti i dati non strutturati da qualsiasi dispositivo, in qualunque posizione? E se sì, quali sono i costi?
- Sicurezza: i dati non strutturati sono considerati sensibili? Possono essere trasferiti e archiviati ovunque? È necessario crittografarli prima che vengano trasmessi in tempo reale e analizzati?
Trasferimento all'edge
Se almeno una di queste domande ti ha fatto riflettere, vale la pena prendere in considerazione l'edge computing. In parole povere, l'edge computing sposta le funzioni applicative più piccole, private o sensibili alla latenza fuori dal datacenter e le colloca vicino alla posizione in cui viene svolto il lavoro effettivo. L'edge computing è già una pratica comune; è impiegato nelle auto che guidiamo e nei telefoni che utilizziamo. Con l'edge computing la scalabilità non è più un problema, ma un vantaggio.
Rileggi il nostro esempio sul settore manifatturiero. Se ogni catena di montaggio avesse un piccolo cluster vicino, tutti i problemi elencati in precedenza potrebbero essere risolti.
- Velocità: le foto delle attività completate vengono esaminate con l'hardware locale, che può funzionare con meno ritardi.
- Quantità: la larghezza di banda verso i siti esterni è notevolmente ridotta, risparmiando sui costi ricorrenti.
- Affidabilità: anche con un calo della connettività della rete WAN, il lavoro può continuare a livello locale ed essere sincronizzato nuovamente con un cloud centrale una volta ristabilita la connettività.
- Scalabilità: indipendentemente dal fatto che gli stabilimenti in questione siano due o 200, le risorse necessarie si trovano in ogni sede. Così si riduce la necessità di sovraccaricare i datacenter centrali per consentire l'operatività anche nei periodi di lavoro più intensi.
- Sicurezza: nessun dato non strutturato lascia la sede, riducendo la potenziale superficie di attacco.
Com'è la combinazione di edge e cloud pubblico?
Red Hat OpenShift, la piattaforma Kubernetes leader del settore, offre un ambiente flessibile che consente di posizionare le applicazioni (e l'infrastruttura) dove è più necessario. In questo caso, non solo l'esecuzione può avvenire in un cloud pubblico centralizzato, ma anche le stesse applicazioni possono essere trasferite alle linee di assemblaggio. Possono acquisire ed elaborare i dati e avviare azioni basate su di essi in modo rapido. Si tratta di procedure di machine learning (ML), che però vengono eseguite all'edge. Diamo un'occhiata a tre esempi in cui l'edge computing viene usato insieme a cloud pubblici e privati. Il primo esempio unisce l'edge computing con un cloud pubblico.

- L'acquisizione dei dati avviene on premise ed è qui che vengono raccolti i dati non strutturati. I sensori e i dispositivi Internet of Things (IoT) che eseguono misurazioni o attività possono connettersi a server edge localizzati utilizzando Red Hat AMQ Streams o il componente broker AMQ. Questi possono variare da piccoli nodi singoli a grandi cluster ad alta disponibilità, a seconda dei requisiti dell'applicazione. Il vantaggio principale è che queste soluzioni possono essere usate insieme in diverse combinazioni, con piccoli nodi in aree remote e cluster più grandi dove c'è più spazio.
- La preparazione dei dati, la creazione di modelli, lo sviluppo delle applicazioni e la distribuzione sono le attività principali. I dati vengono acquisiti, archiviati e analizzati. Prendendo come esempio la catena di montaggio, le immagini dei widget vengono analizzate per individuare gli elementi ripetuti (ad esempio, difetti nei materiali o nei processi). È in questa fase che avviene l'apprendimento vero e proprio. Dopo l'acquisizione di nuove conoscenze, le informazioni vengono reintegrate nelle applicazioni cloud native situate all'edge. Ora, questi processi non vengono svolti all'edge perché l'esecuzione di unità centrali e di elaborazione grafica (CPU/GPU) su cluster densi e centralizzati accelera il processo di alcuni giorni o settimane rispetto all'esecuzione su dispositivi edge leggeri.
- Utilizzando Red Hat OpenShift Pipelines e GitOps, gli sviluppatori possono migliorare continuamente le applicazioni utilizzando integrazione e distribuzione continue (CI/CD) per velocizzare al massimo il processo. Quanto più rapidamente è possibile utilizzare le conoscenze acquisite, tanto più il tempo e le risorse possono essere impiegati in modo efficace per la generazione del fatturato. Ritorniamo quindi all'edge, dove le app nuove e aggiornate basate sull'intelligenza artificiale utilizzano le nuove conoscenze per osservare e acquisire i dati prima di confrontarli con i modelli recenti. Questo ciclo viene poi ripetuto per favorire il miglioramento continuo.
Com'è la combinazione di edge e cloud privato?
Passando al secondo esempio, l'intero processo è identico, ad eccezione della fase 2, che ora avviene on premise in un cloud privato.

Le aziende possono scegliere un cloud privato perché:
- Possiedono già l'hardware e possono utilizzare il capitale esistente.
- Devono rispettare normative rigorose in materia di localizzazione e sicurezza dei dati. I dati sensibili non possono essere archiviati in (o transitare da) un cloud pubblico.
- Hanno bisogno di hardware personalizzato come gate array programmabili sul campo, GPU o un tipo di configurazione che non è disponibile per il noleggio presso un provider di cloud pubblico.
- Hanno carichi di lavoro specifici che è più conveniente eseguire sull'hardware locale che non su un cloud pubblico.
Questi sono solo alcuni esempi della flessibilità offerta da OpenShift. Per esempio, è possibile anche seguire OpenShift su un cloud privato di Red Hat OpenStack Platform.
Com'è la combinazione di edge e cloud ibrido?
L'esempio finale prende in esame il caso di un cloud ibrido composto da cloud pubblici e privati.
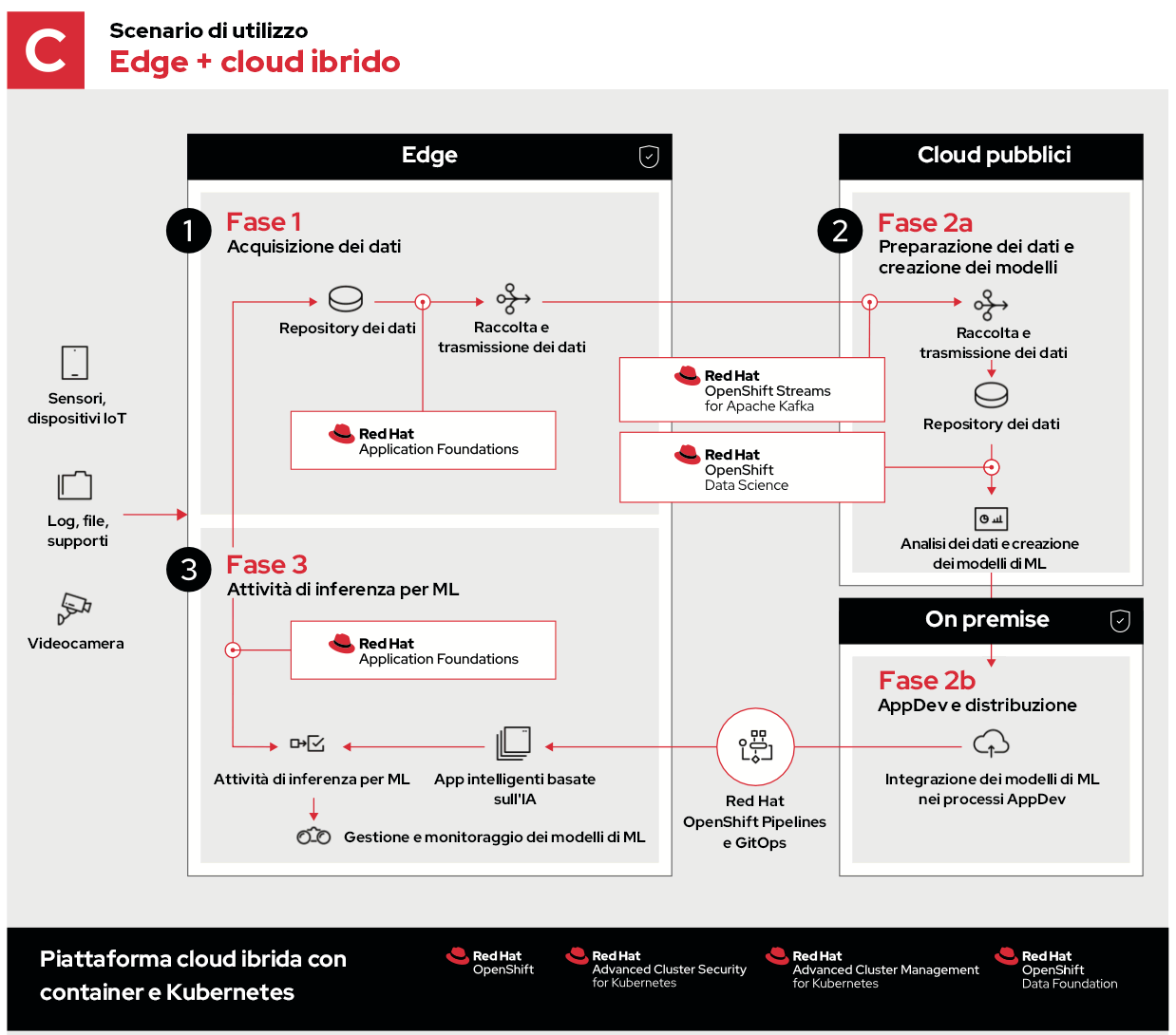
In questo caso, le fssi 1 e 3 sono identiche e anche la fase 2 prevede gli stessi processi, che però vengono distribuiti per essere eseguiti negli ambienti ideali.
- La fase 2a prevede l'acquisizione, l'archiviazione e l'analisi dei dati provenienti dall'edge. In questa fase vengono sfruttate la portata delle risorse, la diversità geografica e la connettività dei cloud pubblici per raccogliere e decifrare i dati.
- La fase 2b consente lo sviluppo di app on premise, ed è possibile accelerare, proteggere o personalizzare in altro modo specifici flussi di lavoro prima di inviare gli aggiornamenti all'edge.
Cosa offre Red Hat?
Considerando il numero di variabili e fattori da tenere in considerazione, un ambiente di edge computing di successo deve essere flessibile. Red Hat offre ai nostri clienti gli strumenti necessari per creare soluzioni flessibili, ottimizzate per eseguire le applicazioni giuste nel posto giusto e soddisfare tante esigenze diverse: gestione una connettività di rete lenta, inaffidabile o nulla, aderenze a norme di conformità rigorose o a requisiti prestazionali estremi e altro ancora.
Indipendentemente dal fatto che le informazioni vengano raccolte all'edge, in un cloud pubblico noto oppure on premise in un cloud privato (o ovunque contemporaneamente), gli sviluppatori possono utilizzare strumenti che già conoscono per innovare continuamente le applicazioni cloud native (su OpenShift) ed eseguirle come e dove preferiscono.
Sull'autore
Ben has been at Red Hat since 2019, where he has focused on edge computing with Red Hat OpenShift as well as private clouds based on Red Hat OpenStack Platform. Before this he spent a decade doing a mix of sales and product marking across telecommunications, enterprise storage and hyperconverged infrastructure.
Altri risultati simili a questo
Le minacce dell'IA si muovono rapidamente. Anche le tue difese dovrebbero farlo.
Dal metallo all'agente: perché l'IA basata sugli agenti è un'evoluzione delle applicazioni
Technically Speaking | Defining sovereign AI with open source
Infrastructure At The Edge | Compiler
Ricerca per canale

Automazione
Novità sull'automazione IT di tecnologie, team e ambienti

Intelligenza artificiale
Aggiornamenti sulle piattaforme che consentono alle aziende di eseguire carichi di lavoro IA ovunque

Hybrid cloud open source
Scopri come affrontare il futuro in modo più agile grazie al cloud ibrido

Sicurezza
Le ultime novità sulle nostre soluzioni per ridurre i rischi nelle tecnologie e negli ambienti

Edge computing
Aggiornamenti sulle piattaforme che semplificano l'operatività edge

Infrastruttura
Le ultime novità sulla piattaforma Linux aziendale leader a livello mondiale

Applicazioni
Approfondimenti sulle nostre soluzioni alle sfide applicative più difficili
Virtualizzazione
Il futuro della virtualizzazione negli ambienti aziendali per i carichi di lavoro on premise o nel cloud