
Why can’t all GPUs live in the data center?
Traditionally, a centralized approach to IT architecture has been the preferred way to address scale, management and environmental issues—and there are certainly use-cases for this approach:
- The datacenters housing the hardware are nice and big
- There’s almost always more room to add additional nodes or hardware—all of which can be managed locally (sometimes even on the same subnet)
- Power, cooling and connectivity are constant and redundant
Why fix a solution that isn’t broken? Well, it’s not that the solution needs fixing… but one-size-fits-all solutions rarely actually fit all. Let’s look at an example using quality control in manufacturing.
Manufacturing quality control
A factory or assembly line can have hundreds—sometimes thousands—of areas where specific tasks are performed on assembly lines. Using a traditional model would require each digital step or real-life tool to not just perform its job, but relay the working result to a central application in a cloud far, far away. This can raise questions, such as:
- Speed: How long does it take a photo to be captured, uploaded to a cloud, analyzed by the central application, a response to be sent and action taken? Do you operate slowly and reduce revenue, or quickly and risk multiple errors or accidents? Are decisions made real time or near real time?
- Quantity: How much network bandwidth is required for every single sensor to be constantly uploading or downloading a stream of raw data? Is that even possible? Is it prohibitively expensive?
- Reliability: What happens if there is a drop in network connectivity; does the entire factory just… stop?
- Scale: Assuming business is good, can a central data center scale to handle every piece of raw data from every device—everywhere? If so, at what cost?
- Security: Is any of the raw data considered sensitive? Is it allowed to leave the area? To be stored anywhere? Does it need to be encrypted before it’s streamed and analyzed?
Moving to the edge
If any of those answers gave you pause, edge computing is worth considering. Put simply, edge computing moves smaller, latency-sensitive or private application functions out of the data center and places them next to where the actual work is being done. Edge computing is already commonplace; it’s in the cars we drive and the phones in our pocket. Edge computing turns scale from a problem into an advantage.
Look at our manufacturing example again. If each assembly line had a small cluster nearby, then all of the above issues could be alleviated.
- Speed: Photos of completed tasks are reviewed on site, with local hardware that can operate with less delay.
- Quantity: Bandwidth to external sites is greatly reduced, saving recurring costs.
- Reliability: Even with a drop in wide-area network connectivity, the work can continue locally and resync to a central cloud when connectivity is reestablished.
- Scale: Whether operating two or 200 factories, the required resources are at each location— reducing the need to overbuild central data centers just to operate during peak times.
- Security: No raw data leaves the premises, reducing the potential attack surface.
What does edge + public cloud look like?
Red Hat OpenShift, the leading enterprise Kubernetes platform, provides a flexible environment that allows applications (and infrastructure) to be placed where it’s needed most. In this case, not only can it run in a centralized public cloud, but those same applications can be moved out to the assembly lines themselves. They can quickly ingest, compute and act on data right there. It’s machine learning (ML)—at the edge. Let’s look at three examples that combine edge computing with private and public clouds. The first combines edge computing and a public cloud.
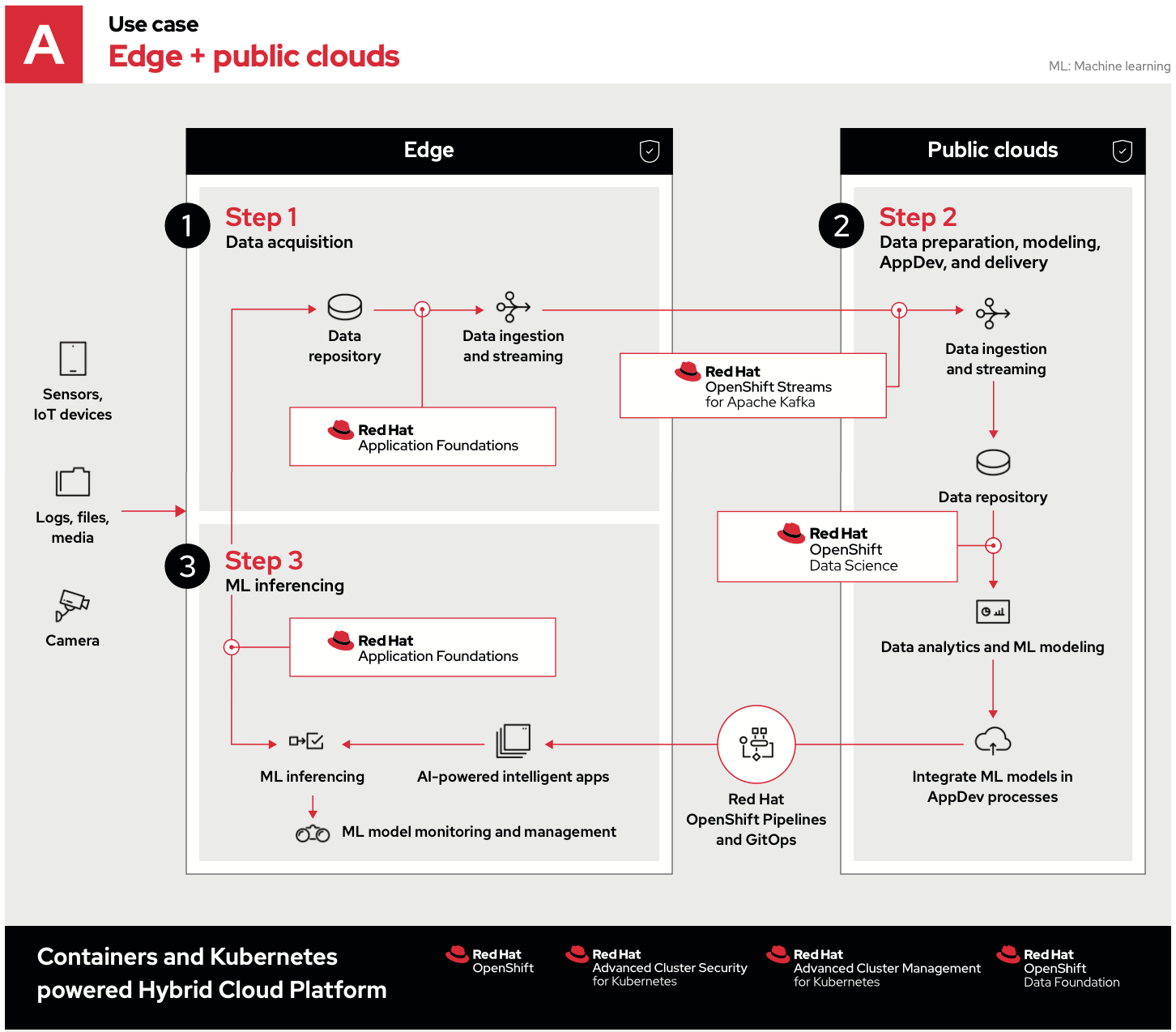
- Data acquisition happens on site and is where the raw data is collected. Sensors and Internet of Things (IoT) devices that take measurements or perform work can connect to localized edge servers using Red Hat AMQ streams or the AMQ broker component. These can range from small single nodes to larger high-availability clusters, depending on the application requirements. Best of all, these can be mixed and matched—with small nodes in remote areas and larger clusters where there’s more space.
- Data preparation, modeling, application development and delivery are where the real work is done. The data is ingested, stored and analyzed. Using the assembly line as an example, images of widgets are analyzed for patterns (such as faults in materials or processes). It’s where the actual learning happens. With new insights gained, this knowledge is then integrated back into the cloud-native applications living at the edge. Now, all this isn’t done at the edge because running intensive central and graphics processing units (CPU/GPU) on dense, centralized clusters speeds up the process by days or weeks when compared to running on lightweight edge devices.
- Using Red Hat OpenShift Pipelines and GitOps, developers can continuously improve their applications using continuous integration and continuous delivery (CI/CD) to make the process as fast as possible. The faster gained knowledge can be used, the more efficiently time and resources can be spent focusing on revenue generation. This brings us back to the edge where the new(ly updated) apps powered by artificial intelligence use new knowledge to observe and ingest data before comparing it to recent models. The cycle repeats as part of continuous improvement.
What does edge + private cloud look like?
Looking at our second example, the entire process is the same with the exception of step 2, which now resides on-premises in a private cloud.
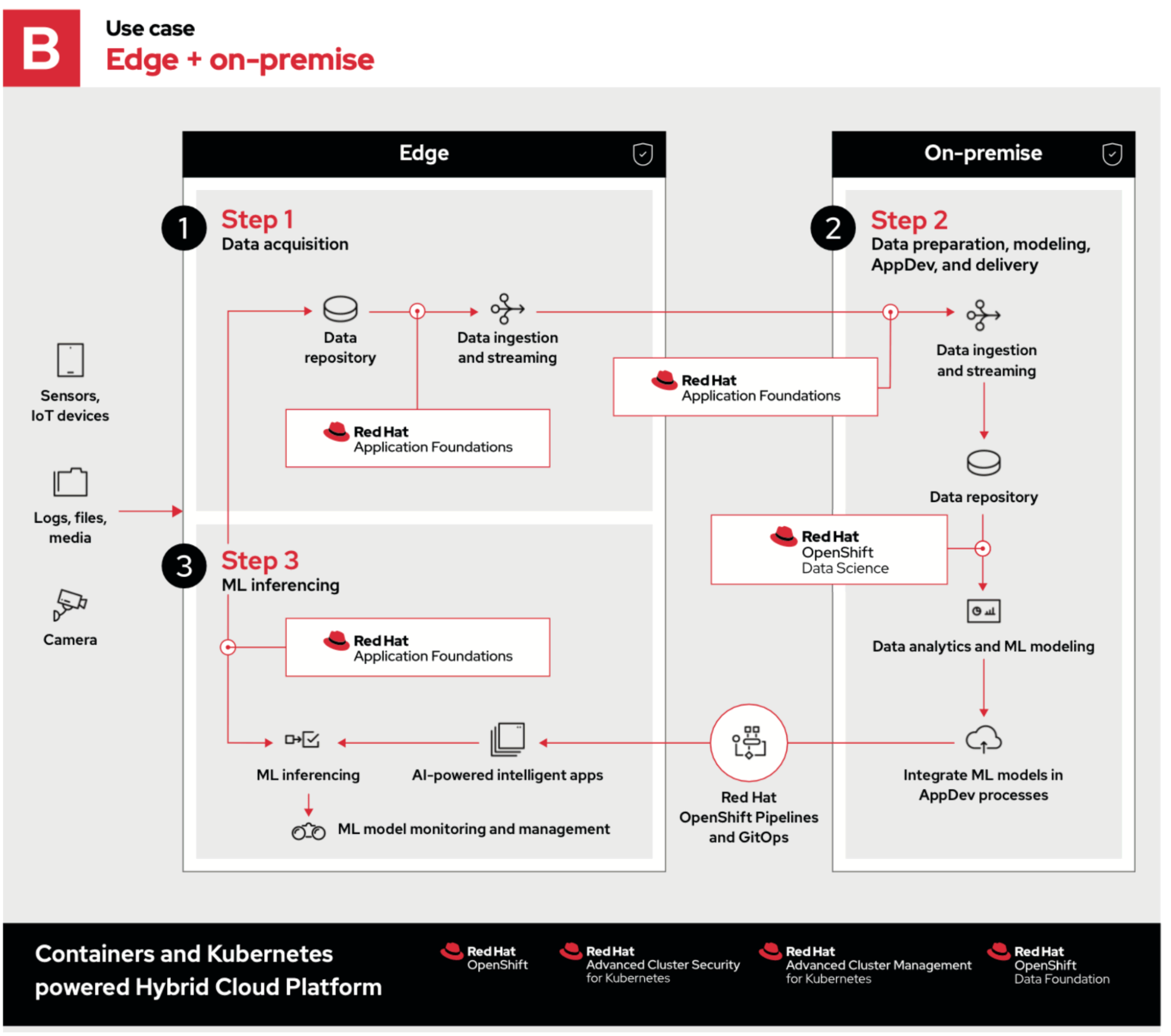
Organizations might choose a private cloud because they:
- Already own the hardware and can use their existing capital.
- Have to adhere to strict regulations about data locale and security. Sensitive data can’t be stored in—or pass through—a public cloud.
- Require custom hardware such as field programmable gate arrays, GPUs or a configuration that simply isn’t available to rent from a public cloud provider.
- Have specific workloads that cost more to run in a public cloud than on local hardware.
These are just a few examples of the flexibility OpenShift allows. It can be as straightforward as running OpenShift on top of a Red Hat OpenStack Platform private cloud.
What does edge + hybrid cloud look like?
The final example uses a hybrid cloud consisting of public and private clouds.
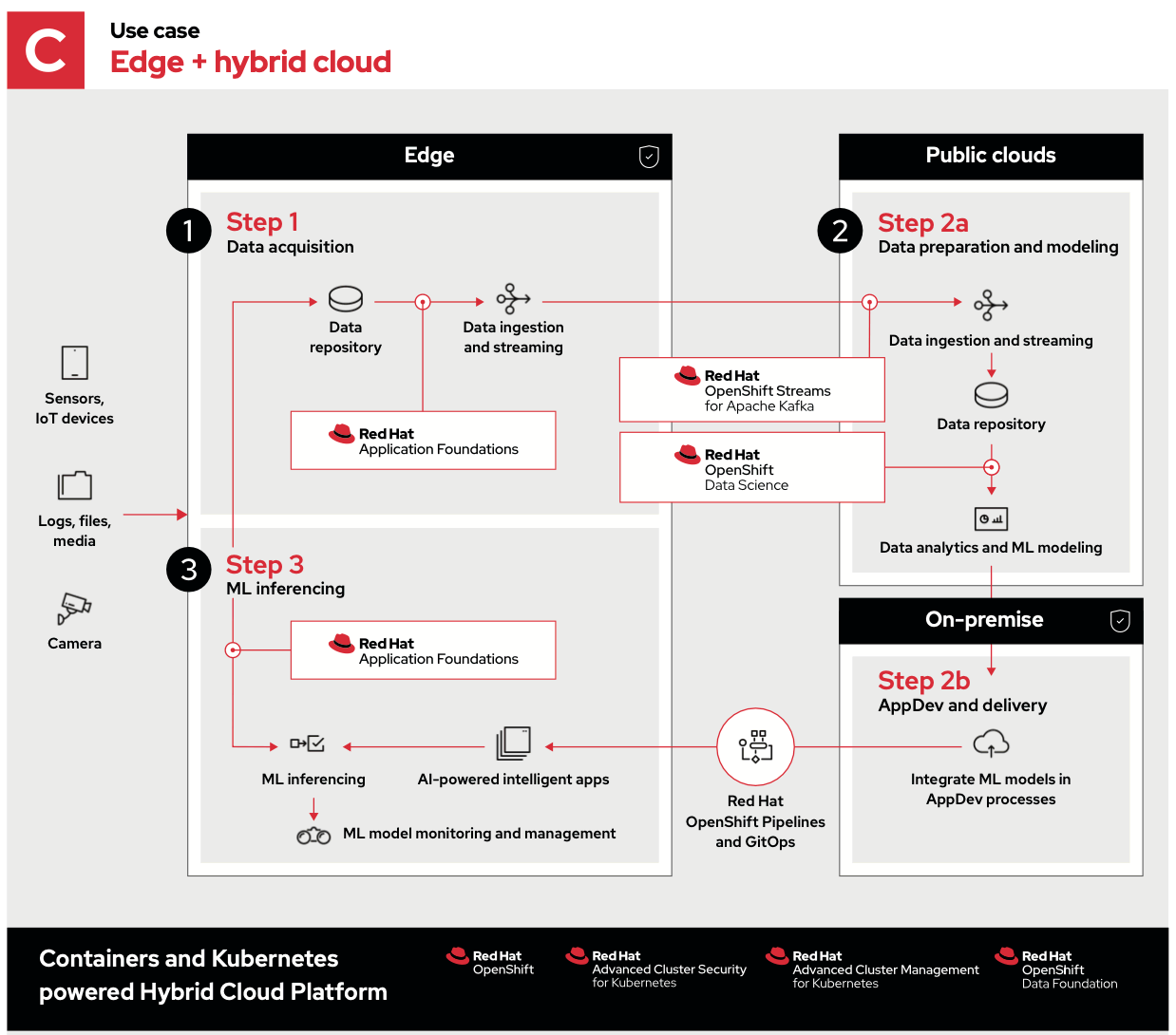
In this case, steps 1 and 3 are the same, and even step 2 has the same processes, however, they’re distributed to run in optimal environments.
- Step 2a is all about ingesting, storing and analyzing data from the edge. This takes advantage of public clouds’ scale of resources, geographic diversity and connectivity to collect and decipher data.
- Step 2b allows for on-premises app development, which can accelerate, secure or otherwise customize specific development workflows before sending those updates back out to the edge.
What does Red Hat offer?
With the number of variables and considerations that need to be taken into account, a successful edge computing environment needs to be flexible. Whether it’s handling slow, unreliable or zero-network connectivity, strict compliance or extreme performance requirements, Red Hat gives our customers the tools they need to build flexible solutions—tuned to run the right applications in the right places.
Whether insights happen at the edge, in a well-known public cloud or on premises in a private cloud (or everywhere all at once), developers can use familiar tools to continuously innovate their cloud-native applications (running on OpenShift) and run them however and wherever is best.
About the author
Ben has been at Red Hat since 2019, where he has focused on edge computing with Red Hat OpenShift as well as private clouds based on Red Hat OpenStack Platform. Before this he spent a decade doing a mix of sales and product marking across telecommunications, enterprise storage and hyperconverged infrastructure.
More like this
Make every GPU-hour count: Progress tracking in Red Hat OpenShift AI
Why self-hosted inference is essential: Building a reliable, sovereign inference layer
Technically Speaking | Defining sovereign AI with open source
Infrastructure At The Edge | Compiler
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds