
OpenShift is Kubernetes with batteries included and verified. That is to say, OpenShift is ready to run complex first- and third-party applications and digital workloads as soon as the installation is complete. For example, every OpenShift cluster includes a software-defined network provider, a container and source build system and registry, an internet-facing router, and even a system for maintaining and updating cluster components. Contrast this with a cluster provisioned by upstream kubeadm or even the more featureful Kubespray, where adding these and other critical features requires thoughtful and sometimes delicate integration.
Not only does OpenShift offer a ready-to-use Kubernetes environment for developers and operators once deployed, but deployment itself has also become remarkably simple despite the many parts. This is especially true when deploying a cluster in a public cloud provider like Amazon Web Services (AWS). Gone are the days when—before cluster installation could even begin—operators and infrastructure teams would have to provision hardware and operating systems and carefully configure and patch datacenter networks; now cloud providers handle that for you.
Though it's still possible to customize OpenShift and its supporting infrastructure to your heart's content, you can meet many use cases with just the defaults, a cloud provider account, and a few well-written commands.
[ Get this complimentary eBook from Red Hat: Managing your Kubernetes clusters for dummies. ]
This article presents three ways to deploy and run OpenShift on AWS and one way to deploy upstream Kubernetes on AWS. I'll describe them in order of increasing complexity and customizability: ROSA, installer-provisioned infrastructure, user-provisioned infrastructure, and Kubespray.
You can follow along and contribute to the code in my GitHub repository.
Option 1: ROSA: Red Hat OpenShift Service on AWS
I'll start with the simplest option: Red Hat OpenShift Service on AWS (ROSA). A ROSA cluster includes deployment, configuration, and management of required compute, network, and storage resources in AWS, as well as all the resources and services of an OpenShift Kubernetes cluster. In contrast to the other options below, Red Hat's operations teams fully support ROSA environments—open a ticket, and an expert Red Hat SRE will attend to it quickly.
Follow along with the scripts.
Set up your tools
The cores of the ROSA lifecycle are the rosa command-line interface (CLI) tool and the OpenShift Cluster Manager (OCM) service. Get the CLI from the Downloads section of the Red Hat Console (complimentary account required) or as a direct download. The source code is in this GitHub repo. The ROSA CLI invokes OpenShift Cluster Manager (OCM) services, which provision the required infrastructure.
You'll need both Red Hat and AWS credentials to enable the rosa CLI to provision and connect to resources. Your AWS credentials can be specified as exported AWS_ACCESS_KEY_ID, AWS_SECRET_ACCESS_KEY, and AWS_REGION environment variables, as for the AWS CLI.
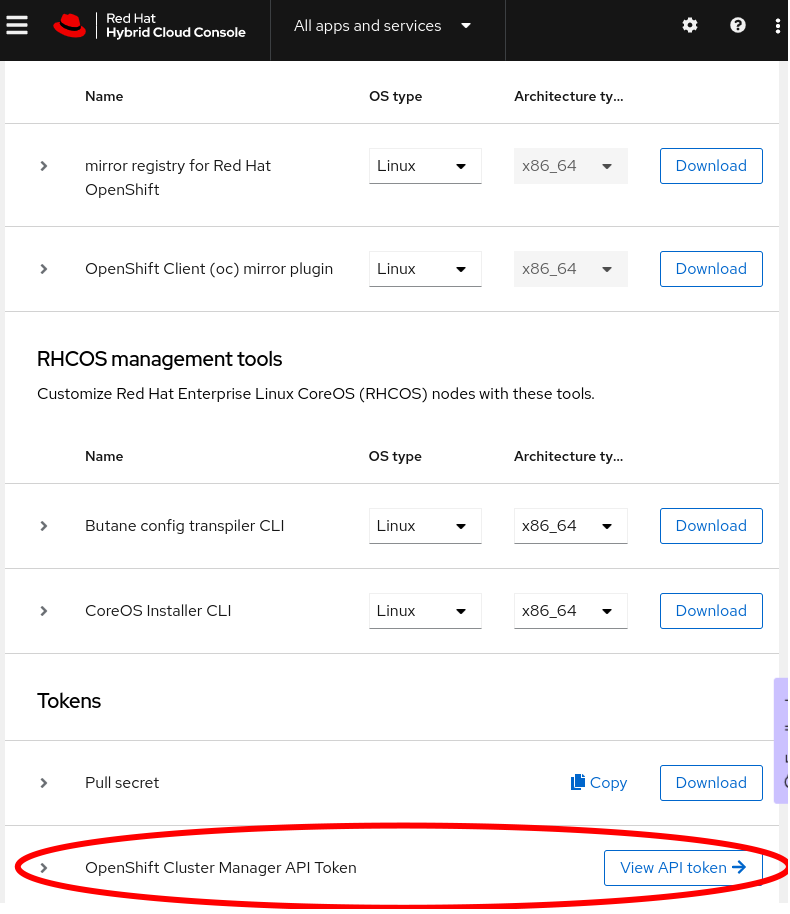
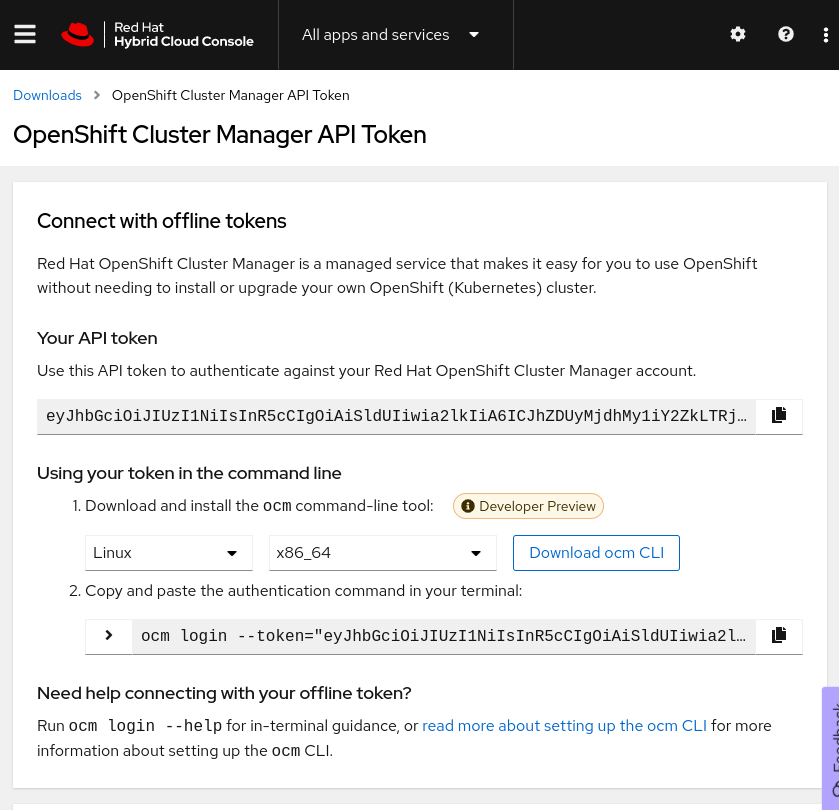
To get a token to log in to your Red Hat account, click View API token at the bottom of the Downloads page (shown in the following screenshots), or follow this direct link. On that page, click Load token, then copy the raw token (not the ocm command line), and run rosa login --token="${your_token}". If successful, you will see this message (with your username, of course): I: Logged in as 'joshgavant' on 'https://api.openshift.com'.
To verify that you've logged in successfully to both accounts, run rosa whoami. If the connections are successful, you'll see a list of attributes for each account.
Tip: To quickly enable autocompletion for rosa commands in your current shell session, run . <(rosa completion).
Create IAM roles
Next, create and link AWS identity and access management (IAM) roles defining the limited permissions granted to the cluster manager service and Red Hat operations team members. In the recommended AWS Security Token Service (STS) mode, these roles are applied to short-lived tokens issued to machine and human operators on demand.
The following commands grant required access to the OCM and its installers. The last command creates roles to act as profiles for the EC2 instances. Several additional roles will be automatically created during installation by specifying --admin and --mode=auto.
$ rosa create --yes ocm-role --admin --mode=auto --prefix="ManagedOpenShift"
$ rosa create --yes user-role --mode=auto --prefix="ManagedOpenShift"
$ rosa create --yes account-roles --mode=auto --prefix="ManagedOpenShift"Create the cluster
Now that your Red Hat account is bound to your AWS account, you can proceed to create your ROSA cluster! Here I'll continue to use the rosa CLI; later I'll mention another approach. Run the following command to create a cluster in STS mode:
$ CLUSTER_NAME=rosa1
$ rosa create --yes cluster --cluster-name "${CLUSTER_NAME}" --sts --mode=auto --watchYou can also interactively provide configuration options when you create the cluster by running rosa create cluster and answering the prompts.
Monitor the installation
By setting the --watch flag in the command above, installation logs will stream to stdout, and the command prompt won't return until the installation completes successfully or fails, typically in about 30 minutes. You can also start watching logs anytime with rosa logs install --cluster ${CLUSTER_NAME} --watch.
[ Deploy an application with Red Hat OpenShift Service on AWS - Overview: How to deploy an application using Red Hat OpenShift Service on AWS. ]
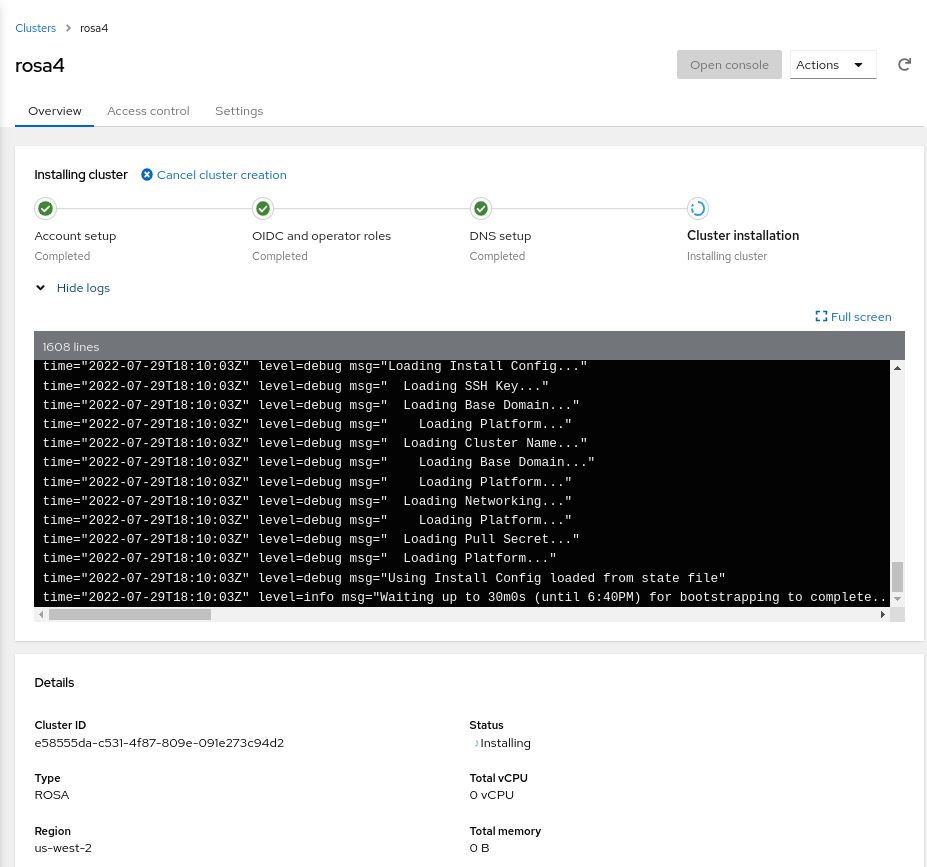
Finally, you can also review logs and other attributes of your new cluster in the Red Hat Console. Click into it and expand the Show logs section to reach a view like the following:
Use the cluster
Once it's ready, the easiest way to begin using your cluster immediately is to create a one-off cluster-admin user. Later you can allow users from a specific OpenIDConnect (OIDC) identity provider using rosa create oidc-provider ...
## create a cluster-admin user
$ rosa create --yes admin --cluster "${CLUSTER_NAME}"You'll need URLs to reach the API server and web console of your new cluster; get those with rosa list clusters. Finally, log in to the cluster via the oc CLI: oc login ${api_server_url} --user cluster-admin --password ${admin_password}.
Create the cluster via the UI
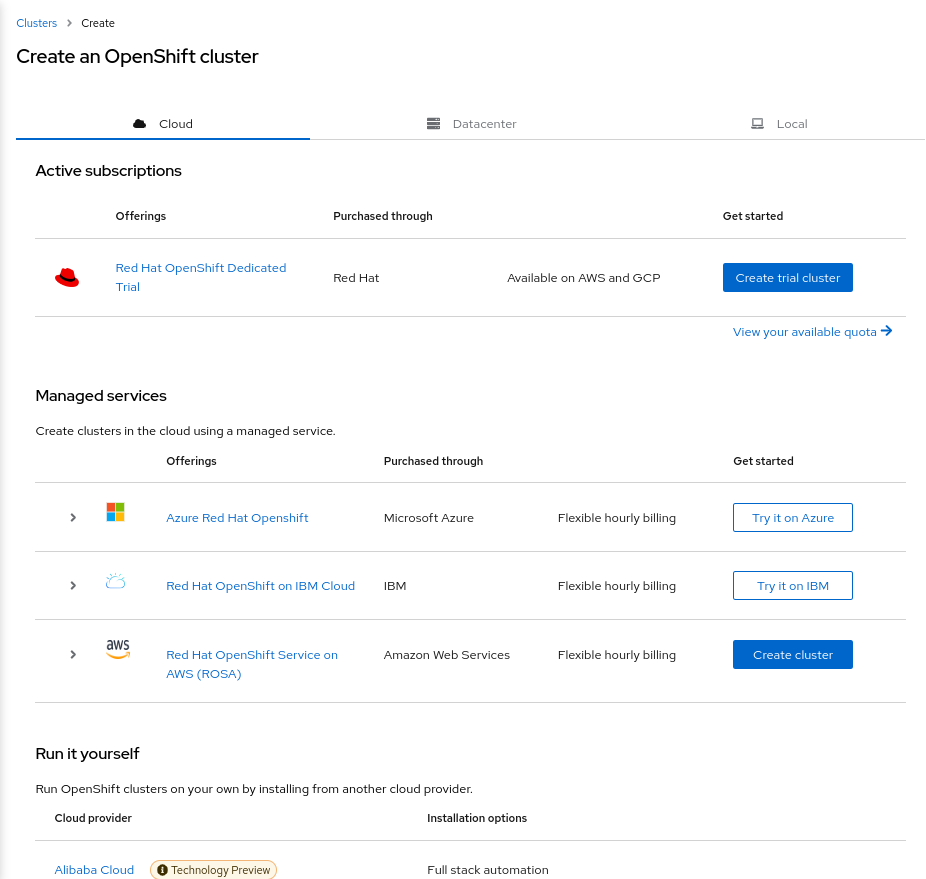
Instead of using the rosa CLI, once you have linked your Red Hat and AWS accounts as described above, you can also create a cluster using a guided graphical wizard in the Console. On the Clusters page on the Console, click Create cluster. On the Cluster create page, click Create cluster next to the ROSA offering.
[ Getting started with Red Hat OpenShift Service on AWS Learning Path - Getting started with Red Hat OpenShift Service on AWS. ]
Option 2: Installer-provisioned infrastructure (IPI)
Even if Red Hat doesn't manage your cluster, it can still be deployed and configured in AWS automatically with a short list of commands. This method sets up EC2 machines, volumes, Virtual Private Cloud (VPC) networks, and the cluster itself. It's known as Installer-provisioned infrastructure (IPI); here's how to do it.
Follow along with the scripts.
Set up your tools
At the heart of IPI and other OpenShift deployment methods is the openshift-install CLI tool. Download it from the downloads section of the OpenShift console or directly. The source code is in this GitHub repo. Run openshift-install create --help for a list of installation steps, which by default proceed as follows:
- install-config: Generate the configuration manifest for the infrastructure and cluster.
- manifests: Generate the required Kubernetes resource manifests.
- ignition-configs: Embed the Kubernetes resource manifests in CoreOS Ignition configuration files.
- cluster: Provision the EC2 machines and bootstrap them with the configuration files created previously.
You'll also need a pull secret with credentials for Red Hat's container registries. You can get this from the OpenShift downloads page.
You need an SSH key pair for access to provisioned machines; you'll need to provide its public key to the installer and save the private key for access. You can copy an existing key from (for example) ~/.ssh/id_rsa.pub or create a new one in a secure place using (for example) ssh-keygen -t rsa -b 4096 -C "user@openshift" -f "./id_rsa" -N ''. Copy the contents of the *.pub file as the value of SSH_PUBLIC_KEY below and save the private key for later.
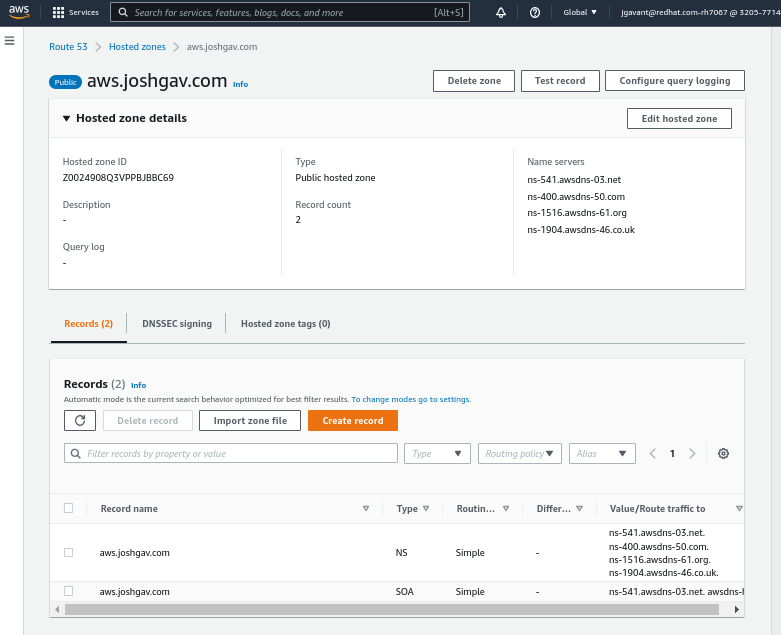
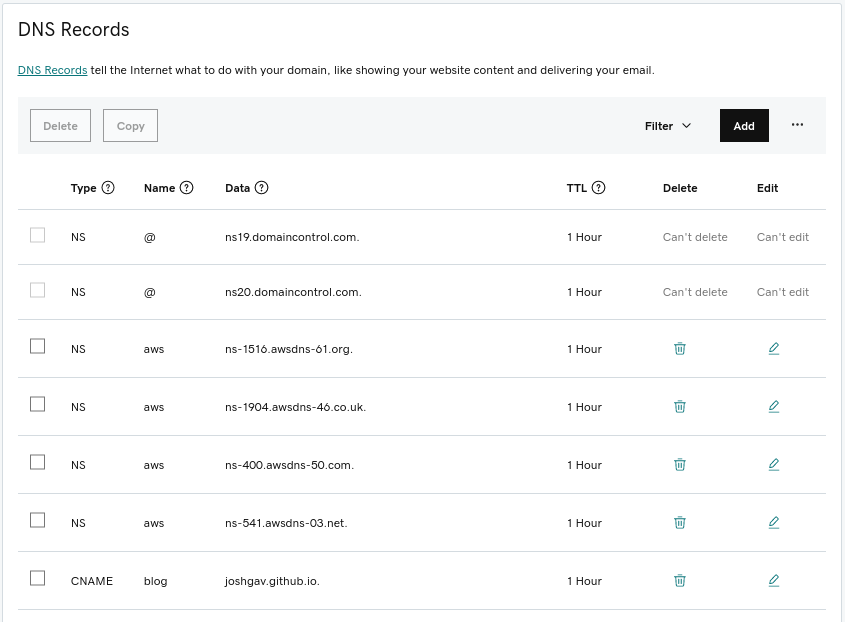
Finally, to be able to access the cluster's API server and web console by name, you'll need an AWS Route53 public hosted zone for your cluster's base domain name. For example, I delegated a domain named aws.joshgav.com from my registrar GoDaddy to a new AWS Route53 zone in the following screenshots. Specifically, after creating the Route53 zone, I create nameserver (NS) records for aws in the parent joshgav.com zone at GoDaddy pointing to the name servers selected by Route53. More details are available from Red Hat and AWS documentation.
Create the cluster
With these prerequisites in place, use openshift-install create ... to manage the phases of the installation process. An automatable approach is to define the desired config of your cluster in a file named install-config.yaml, put it in a directory ${WORKDIR}, and run the installer in the context of that directory, like so: openshift-install create cluster --dir ${WORKDIR}.
[ Want to test your sysadmin skills? Take a skills assessment today. ]
The following is a template install-config.yaml file. Use your own values for OPENSHIFT_PULL_SECRET, YOUR_DOMAIN_NAME, and SSH_PUBLIC_KEY established above. (Note: Find the schema for install-config.yaml here.)
apiVersion: v1
metadata:
name: ipi
baseDomain: ${YOUR_DOMAIN_NAME}
controlPlane:
architecture: amd64
hyperthreading: Enabled
name: master
platform: {}
replicas: 3
compute:
- architecture: amd64
hyperthreading: Enabled
name: worker
platform: {}
replicas: 3
networking:
networkType: OVNKubernetes
clusterNetwork:
- cidr: 10.128.0.0/14
hostPrefix: 23
machineNetwork:
- cidr: 10.0.0.0/16
serviceNetwork:
- 172.30.0.0/16
platform:
aws:
region: us-east-1
publish: External
pullSecret: '${OPENSHIFT_PULL_SECRET}'
sshKey: '${SSH_PUBLIC_KEY}'Monitor the installation
The cluster installation will take 30 minutes or more. Watch logs stream to stdout by using the openshift-install create cluster command, running openshift-install wait-for install-complete, or tailing the .openshift_install.log file in the installation working directory to track the progress of infrastructure and cluster installation.
Internally, openshift-install deploys infrastructure as described in these Terraform configs, and many log entries come from Terraform.
Use the cluster
You can find a username and password for your cluster in the final lines of the install log, either on stdout or in the .openshift_install.log file in the working directory. In addition, a kubeconfig file and the kubeadmin user's password are saved in the auth directory of the installation directory. Log in to your cluster using one of the following mechanisms:
## using kubeconfig with embedded certificate
$ export KUBECONFIG=temp/_workdir/auth/kubeconfig
## using username and password
$ oc login --user kubeadmin --password "$(cat temp/_workdir/auth/kubeadmin-password)"
## verify authorization
$ oc get pods -AOption 3: User-provisioned infrastructure (UPI)
Though the easiest ways to get started with OpenShift on AWS are with ROSA or IPI, Red Hat also enables you to deploy and configure your own cloud infrastructure—machines, networks, and storage—and provision a cluster on those using the user-provisioned infrastructure (UPI) method.
Follow along with the scripts.
[ Learn how to manage your Linux environment for success. ]
Set up your tools
Like IPI installations, UPI installations use openshift-install and the other prerequisites to generate resource manifests and OpenShift configuration files. Unlike IPI, the user must configure machines and supply these files to them when needed. In AWS, this is typically accomplished by putting configurations in an S3 bucket and asking machines to retrieve them from the bucket's URL on startup.
Create the cluster
To guide users in provisioning their own infrastructure, Red Hat provides a set of CloudFormation templates reflecting good patterns for OpenShift clusters. One way to deploy these is as implemented in this script.
Creating a UPI cluster in AWS follows these steps:
- Initialize Kubernetes manifests and OpenShift configurations with
openshift-install. - Deploy AWS networks and machines using recommended CloudFormation templates or equivalent mechanisms, bootstrapping machines from generated configurations.
- Await completed installation using
openshift-install.
The AWS resources recommended for OpenShift include a VPC and subnets, a DNS zone and records, load balancers and target groups, IAM roles for EC2 instances, security groups, and even an S3 bucket. Several types of cluster nodes are also included—bootstrap, control plane, and worker. The bootstrap machine starts first and installs the production cluster on the other machines.
You can find complete instructions for AWS UPI in OpenShift's documentation.
Monitor the installation
Once EC2 instances start and installation of the bootstrap and production clusters begins, you can monitor progress using openshift-install wait-for [install-complete | bootstrap-complete] in your working directory. As with other methods, the installation will probably take more than 30 minutes.
One step in cluster provisioning is intentionally difficult to automate—approving certificate signing requests (CSRs) for nodes. Ideally, an administrator should verify the provenance of a CSR is the expected node before approving the request. You can check if CSRs are awaiting approval with oc get csr. Approve all pending requests with something like:
csrs=($(oc get csr -o json | jq -r '.items[] | select(.status == {}) | .metadata.name'))
for csr in "${csrs[@]}"; do
oc adm certificate approve "${csr}"
doneIn the sample scripts that accompany this article, this check runs in the background while the cluster is being provisioned so that CSRs are immediately approved.
Use the cluster
You don't use the openshift-install create cluster command with UPI. Instead, run openshift-install wait-for install-complete after the installation process starts. As with IPI, you can monitor the stdout of this command or the .openshift_install.log file for information on the cluster installation's progress. When the cluster is ready, log in as above with oc login as the kubeadmin user with the password in ${workdir}/auth/kubeadmin password, or set your KUBECONFIG env var to the path ${workdir}/auth/kubeconfig.
Once ready, reach the cluster's console at https://console-openshift-console.apps.${CLUSTER_NAME}.${BASE_DOMAIN}/.
Option 4: Kubernetes with Kubespray
The previous sections described how to deploy OpenShift on AWS with various levels of support and automation for provisioning and operation. In this section, I'll show how to deploy upstream Kubernetes using Kubespray to compare, contrast, and gather new ideas. I've chosen Kubespray over kubeadm for this exercise because it offers a more complete deployment closer to OpenShift's experience.
Follow along with the scripts.
Kubespray's included configuration for AWS infrastructure yields the following environment, nearly identical to that produced by openshift-install and ROSA.

As with UPI for OpenShift, with Kubespray, you first install the infrastructure as you want (for example with Terraform or CloudFormation) and then use Kubespray to install a cluster on that infrastructure. Kubespray offers Terraform configurations for deploying typical environments on cloud providers. For this example, I used the configurations for AWS.
Create a cluster
The last step of infrastructure provisioning creates an inventory file for Ansible to consume to deploy cluster components. When the infrastructure is deployed and the inventory file is ready, run the main Kubespray process—an Ansible playbook—using that inventory, for example, ansible-playbook -i hosts.ini cluster.yaml. Customize the deployment by changing variables in inventory vars files or passing -e key=value pairs to the ansible-playbook invocation. See the deploy-cluster.sh script in the walkthrough for an example.
[ Try this tutorial to learn Ansible basics. ]
Rather than installing the Kubespray Ansible environment locally, you may prefer to run commands in a containerized process bound to your inventory and SSH files:
$ podman run --rm -it \
--mount type=bind,source=kubespray/inventory/cluster,dst=/inventory,relabel=shared \
--mount type=bind,source=.ssh/id_rsa,dst=/root/.ssh/id_rsa,relabel=shared \
quay.io/kubespray/kubespray:v2.19.0 \
bash
# when prompted, enter (for example):
$ ansible-playbook cluster.yml \
-i /inventory/hosts.ini \
--private-key /root/.ssh/id_rsa \
--become --become-user=root \
-e "kube_version=v1.23.7" \
-e "ansible_user=ec2-user" \
-e "kubeconfig_localhost=true"Use the cluster
The Ansible variable kubeconfig_localhost=true indicates that a kubeconfig file with credentials for the provisioned cluster should be written to the inventory directory once the cluster is ready. You can use this config to authenticate to the cluster's API server and invoke kubectl commands.
Initially, the kubeconfig file will use an internal AWS IP address for the API server location. To manage your cluster from outside AWS, you'll need to change the server's URL to the address of your externally accessible load balancer (provisioned by Terraform previously). You can find the external load balancer URL:
aws elbv2 describe-load balancers --output json | jq -r '.LoadBalancers[0].DNSName'Replace the server URL in the kubeconfig file with this hostname. Be sure to prepend https:// and append :6443/.
Finally, set your KUBECONFIG env var to the file's path: export KUBECONFIG=inventory/cluster/artifacts/admin.conf and then run kubectl get pods -A. If all is well, you should get a list of all pods in the cluster.
Wrapping up
In this article and accompanying code, I've discussed and demonstrated how to deploy an OpenShift or upstream Kubernetes cluster in AWS using four different methods, which progress from simplest with least control to most complex yet customizable.
To minimize the complexity and overhead of managing your own clouds and clusters, start with the simplest method—ROSA—and progress to others as you need greater control and customization. Please provide feedback in the repo. Thanks!
This article originally appeared on the author's blog and is republished with permission.
About the author
Josh has contributed to the cloud computing industry for some 15 years as a platform architect and engineer and today serves cloud users and enterprises as a cloud solution architect at Red Hat. He's passionate about learning and advocating for the requirements of cloud users as well as developing content and code to enable them to succeed.
More like this
Why Red Hat partners are the ultimate telco business asset
Reclaiming infrastructure autonomy: The 180-day mandate for virtualization service providers
Air-gapped Networks | Compiler
The Containers_Derby | Command Line Heroes
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds