Backing up persistent volumes (PVs) from one Kubernetes cluster to another is useful if you want a hot standby site for failover during maintenance or a disaster. There are multiple ways to tackle this problem, including:
- The Red Hat OpenShift Application Data Protection (OADP) operator
- OpenShift Data Foundations (ODF) Disaster Recovery tooling
- Various third-party solutions
I like using VolSync because it is lightweight compared to the ODF solution and doesn't require a full ODF cluster. In addition, it is part of Red Hat Advanced Cluster Management (ACM) for Kubernetes.
[ Learn how to extend the Kubernetes API with operators. ]
My hub, spoke1, and spoke2 are all single-node (SNO) OpenShift Container Platform (OCP) clusters running OCP version 4.11.25 and ACM 2.7.0. The ODF/LVM operator is installed first on each cluster, followed by a partial installation of ODF using the storage class created by ODF/LVM (odf-lvm-vg1).
The application running on spoke1 supports my blog site. It is a Ghost-based deployment, and the latest version of Ghost has two persistent volumes to back up. One is for the database, and the other is for the content (mostly pictures/graphics). I will show how I back up one of those volumes.
This article covers the following topics:
- Installing the VolSync add-on
- Setting up MetalLB
- Setting up the ReplicationDestination Custom Resource Definition (CRD) on spoke2
- Setting up the ReplicationSource CRD on spoke1
- Mounting this as a permanent volume in case of disaster or maintenance
1. Install the VolSync add-on
The following steps summarize the information in the ACM add-ons docs.
Since my environment is bare metal, I will follow the appropriate steps for that use case. The YAML files I reference are available on my GitHub site.
To deploy VolSync, on the hub cluster, apply the ManagedClusterAddOn for VolSync in the spoke1 and spoke2 clusters namespace:
apiVersion: addon.open-cluster-management.io/v1alpha1
kind: ManagedClusterAddOn
metadata:
name: volsync
namespace: spoke1
spec: {}
$ oc apply -f mca-volsync-spoke1.yaml
apiVersion: addon.open-cluster-management.io/v1alpha1
kind: ManagedClusterAddOn
metadata:
name: volsync
namespace: spoke2
spec: {}
$ oc apply -f mca-volsync-spoke2.yaml
The next steps are optional and only for learning purposes.
When you deploy these two YAML files, check whether the status is true. It will show unknown first but should change to true shortly after.
$ oc get ManagedClusterAddOns -A|grep volsync

Some other magic happens in the background. You will see the VolSync operator automatically added to the spoke1 and spoke2 clusters, and some workloads will be created to support this on the hub, spoke1, and spoke2 clusters.

On the hub cluster, a VolSync controller is running:
$ oc get po -A|grep volsync
The following pods are created on spoke1 and spoke2. There is also a controller manager running at this point:
$ oc get po -A|grep volsync
The VolSync operator exposes two new CRDs called ReplicationSource and ReplicationDestination. In the following text, note that the ReplicationSource object will exist on the cluster (spoke1) that is the source of the persistent volume.
The ReplicationDestination object will be created on the destination cluster (spoke2).
2. Set up the MetalLB operator
In my environment, I have a constant VPN connection between all my cluster endpoints, meaning they can all reach each other using 192.168.x.x IPs (RFC 1918). You will need some way for your clusters to communicate, whether using the Submariner add-on (which I'll explain in a follow-up article) or exposing a service with a load balancer.
[ Learning path: Getting started with Red Hat OpenShift Service on AWS (ROSA) ]
Since my environment is bare metal, I can't create a load balancer resource automatically, like I can in cloud-based environments such as AWS, GCP, or Azure. I need to use the MetalLB operator to get similar functionality in my cluster.
This operator exposes the service used on the destination cluster (spoke2), which will have an SSH endpoint because I'm using rsync for this demo. When I create the ReplicationDestination CRD, an address will be created based on the ip-pool setup in MetalLB.
1. First, install MetalLB on the destination cluster (spoke2).
2. On the OpenShift Console, go to Operators > OperatorHub and search for MetalLB:

Click on Install. On the following screen, accept the defaults. (Disregard the warning in my screenshot about the existing namespace. I didn't fully clean up the operator from my previous run.)
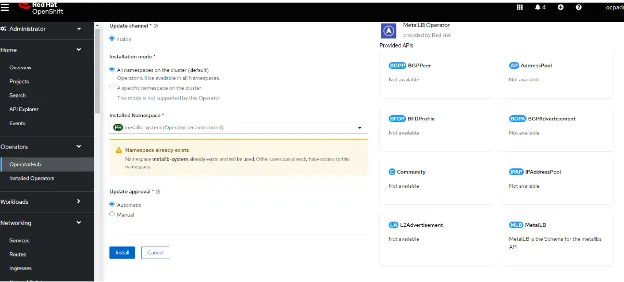
Click Install again and wait for the operator to finish installing.
The interface says "ready for use" when the MetalLB operator is installed:
3. Next, create the MetalLB CRD. Go to Operators > Installed Operators > MetalLB, and click on Create instance for MetalLB:

4. Accept the defaults on this screen and click Create:
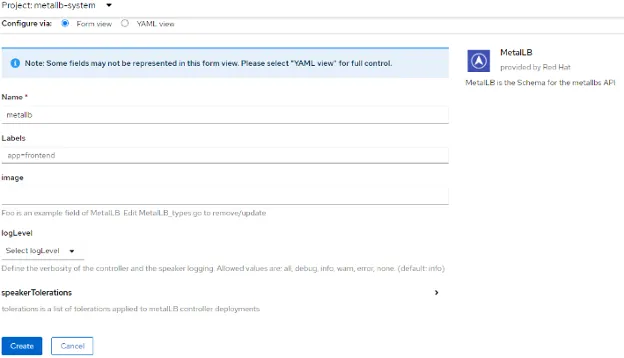
5. Shortly after creating the MetalLB CRD, the resource will show as Available:

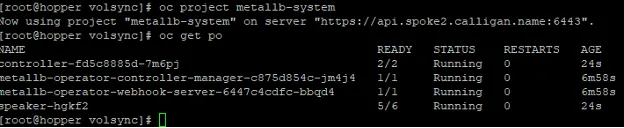
6. Next, review what was created on the spoke2 cluster. This step is optional.
$ oc project metallb-system
$ oc get po
7. Use the ip-pool.yaml file from the same GitHub repo you worked with previously.
Ensure the IP address range is on the same subnet as the spoke2 SNO cluster and reachable from the spoke1 cluster. If you only want to expose port 22/SSH, that is fine.
apiVersion: metallb.io/v1beta1
kind: IPAddressPool
metadata:
namespace: metallb-system
name: spoke2-ips
labels:
spec:
addresses:
- 192.168.102.246-192.168.102.254
$ oc apply -f ip-pool.yaml
When applying this configuration, you may see that some of the load balancer services associated with noobaa/s3 bucket storage in the openshift-storage namespace now have an IP addresses from the pool created above.
$ oc get svc -A|grep openshift-storage|grep LoadBalancer

One additional step relates to MetalLB, which is associated with the layer2 advertisement. The next section shows the impact of not having this applied.
[ Learn how to build a flexible foundation for your organization. Download An architect's guide to multicloud infrastructure ]
3. Set up the ReplicationDestination CRD on spoke2
Set up the ReplicationDestination first because you need some information from this object to create the ReplicationSource, such as the IP address and SSH key.
The ReplicationDestination resource on spoke2 looks like this:
apiVersion: volsync.backube/v1alpha1
kind: ReplicationDestination
metadata:
name: myopenshiftblog
namespace: myopenshiftblog
spec:
rsync:
serviceType: LoadBalancer
copyMethod: Snapshot
capacity: 20Gi
accessModes: [ReadWriteOnce]
storageClassName: odf-lvm-vg1
volumeSnapshotClassName: odf-lvm-vg1
$ oc create -f replicationdestination.yaml
This process creates resources to house the backup of the persistent volumes from the source (spoke1).
I created my backup resource in the namespace/project called myopenshiftblog, so that is where the resulting resources will be shown. Adjust this for your environment:
$ oc project myopenshiftblog
$ oc get po
$ oc get svc
You should see a pod running called volsync-rsync..... and a service that exposes an external IP based on the range of IPs exposed by the MetalLB load balancer.

The external IP is needed for creating the ReplicationSource CRD on spoke1.
It's also important to note that the external IP listens only on port 22, which is needed for SSH. It won't ping from anywhere.
To verify that the external IP is reachable from spoke1, run the following command:
$ telnet 192.168.102.249 22
In my case, it wasn't reachable. One reason is that MetalLB needs another component to announce this IP.
Create an L2 advertisement CRD since the 192.168.102.249 IP does not know how to route (I never gave it a gateway).
apiVersion: metallb.io/v1beta1
kind: L2Advertisement
metadata:
name: l2advertisement
namespace: metallb-system
spec:
ipAddressPools:
- spoke2-ips
Reference the IP address pool you created earlier (the spoke2-ips, in my case).
Now, check the result of the telnet command again from spoke1:
$ telnet 192.168.102.249 22
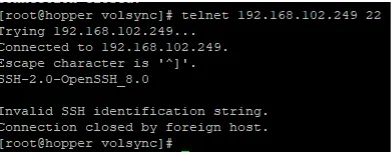
That is better.
One last piece of information is needed to create the ReplicationSource CRD on spoke1: the public key of the destination endpoint so that spoke1 can connect without a password.
On spoke2, run the following commands (adjust based on your setup) to get the address (this is another way) and the contents of the SSH key:
$ oc get replicationdestination <destination> -n <destination-ns> --template={{.status.rsync.address}}`
$ oc get replicationdestination <destination> -n <destination-ns> --template={{.status.rsync.sshKeys}}
These two outputs report that the IP address is 192.168.102.249, and the secret that contains the info is called volsync-rsync-dst-src-myopenshiftblog.
Save the contents of this secret to a text file:
$ oc get secret volsync-rsync-dst-src-myopenshiftblog -o yaml
This secret will contain the private/public key for the source cluster and the public key of the destination to be used. Here is some sample output of the secret:
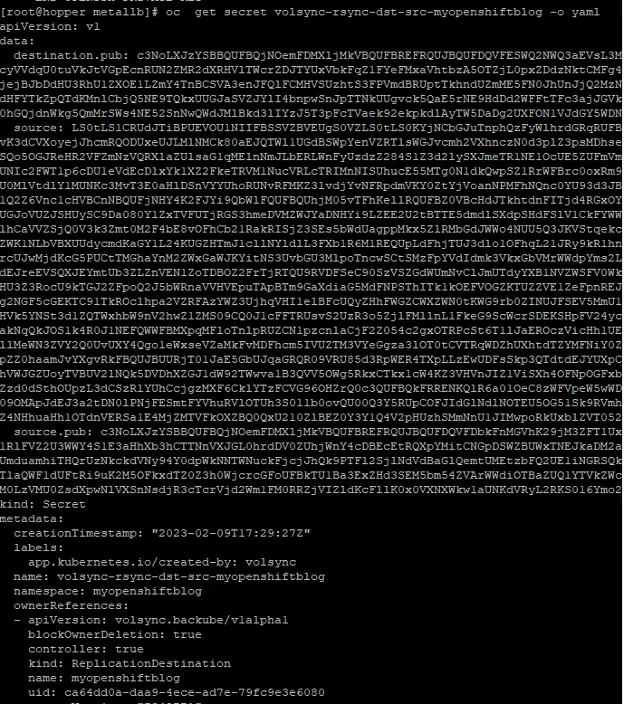
You need to edit this file in your text editor to remove the ownerReferences, resourceVersion, and uid. You will put this information into the spoke1 cluster shortly.
4. Set up the ReplicationSource CRD on spoke1
Apply the contents of the secret to the source cluster (spoke1). Make sure everything you create is in the same namespace.
I called my namespaces the same on both clusters (myopenshiftblog).
Here is a sample of the formatted secret. This information is randomly generated each time. Keep the same secret name as well.

$ oc create -f volsync-rsync-dst-src-myopenshiftblog.yaml
Next, create the ReplicationSource CRD:
apiVersion: volsync.backube/v1alpha1
kind: ReplicationSource
metadata:
name: myopenshiftblog
namespace: myopenshiftblog
spec:
sourcePVC: myopenshiftblog-content
trigger:
schedule: "*/3 * * * *" #/*
rsync:
sshKeys: volsync-rsync-dst-src-myopenshiftblog
address: 192.168.102.249
copyMethod: Snapshot
storageClassName: odf-lvm-vg1
volumeSnapshotClassName: odf-lvm-vg1
$ oc create -f replicationsource.yaml
When this resource is created, a few things will happen.
Since this job runs every 3 minutes, you should see a sync job start:
$ oc get replicationsource

This command shows when the last sync started, the duration, and when the next sync will occur.
Look at the spoke2 cluster to see if the snapshot/PV exists. I will use the console for this example.
The VolumeSnapshot object exists. You can use this information for restoration purposes.

The PersistentVolumeClaim and PV exist, which contain the source data.

Look inside the destination pod on spoke2, which mounts the persistent volume as /data.
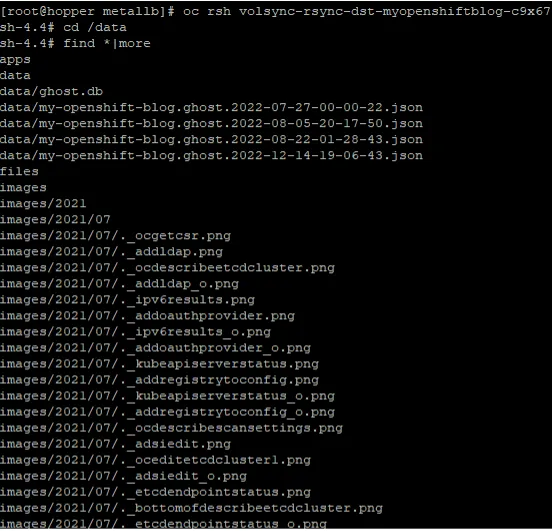
This result shows the PV was copied, and the data is there.
[ Become a Red Hat Certified Architect and boost your career. ]
5. Mount the snapshot as a permanent volume in case of disaster or maintenance
If you want to use this VolumeSnapshot on spoke2 to create a permanent volume, here is a sample YAML. The necessary steps follow.
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: <pvc-name>
namespace: <destination-ns>
spec:
accessModes:
- ReadWriteOnce
dataSource:
kind: VolumeSnapshot
apiGroup: snapshot.storage.k8s.io
name: <snapshot_to_replace>
resources:
requests:
storage: 20Gi
Adjust this file as appropriate and apply it.
Your workloads (deployments, pods, and so forth) can then claim this persistent volume.
Wrap up
My next article shows how to do this operation using Submariner. That add-on allows you to use ClusterIP resources (instead of LoadBalancer) to enable services to be reachable across multiple clusters.
Additional references:
This originally appeared on myopenshiftblog and is republished with permission.
About the author

Keith Calligan is an Associate Principal Solutions Architect on the Tiger Team specializing in the Red Hat OpenShift Telco, Media, and Entertainment space. He has approximately 25 years of professional experience in many aspects of IT with an emphasis on operations-type duties. He enjoys spending time with family, traveling, cooking, Amateur Radio, and blogging. Two of his blogging sites are MyOpenshiftBlog and MyCulinaryBlog.
More like this
Ford's keyless strategy for managing 200+ Red Hat OpenShift clusters
F5 BIG-IP Virtual Edition is now validated for Red Hat OpenShift Virtualization
Scaling For Complexity With Container Adoption | Code Comments
Kubernetes and the quest for a control plane | Technically Speaking
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds