In a previous article, we focused on the capability that turns large language models (LLMs) from general-purpose tools into instruments of research through domain-specific customization. Fine-tuned models are how research teams encode domain expertise, institutional research, and reasoning patterns into systems that can help accelerate discovery rather than simply assist it.
But customized models are only one half of the equation. For those models to become useful at institutional scale, they need a platform that can be used to train, serve, govern access to, and integrate them into the broader research computing environment. That platform must bridge the worlds researchers already live in—traditional high performance computing (HPC) clusters running the Slurm workload manager and the rapidly expanding cloud-native AI ecosystem built on Kubernetes.
In this article we explore how that platform comes together—the architecture that allows research institutions to converge HPC and cloud-native workloads, operationalize customized models as shared services, and deliver generative AI (gen AI) capabilities across entire organizations without sacrificing governance, reproducibility, or cost control.
The platform architecture: How the pieces fit together
With the customization case established, let's look at how the full platform comes together. The architecture is generalized, and it applies whether you're building it at a research university, a federally funded research and development center, a teaching hospital, an energy company, or a financial services research group. The components are the same, but the configuration for each domain differs.
The foundation is Red Hat OpenShift, a Kubernetes distribution that provides the container orchestration, namespace governance, role-based access control (RBAC), persistent storage integration, and operational tooling that platform engineers need to run a shared AI infrastructure at institutional scale.
On top of OpenShift, Red Hat OpenShift AI provides AI-specific capabilities, including model serving, model customization, pipeline orchestration, notebook environments for data scientists, and observability for AI workloads. OpenShift AI transforms the base Kubernetes platform into an environment where researchers can train, fine-tune, evaluate, deploy, and monitor models through a governed, self-service interface—without each team needing to manage their own machine learning (ML) infrastructure.
The inference engine is vLLM, served through OpenShift AI's model serving layer. vLLM's continuous batching and memory-efficient attention mechanisms make it the right choice for shared inference environments where multiple research teams are consuming model endpoints concurrently. In a resource-constrained environment—which is most research institutions—the difference between efficient and inefficient inference is a meaningful share of the GPU budget.
The Red Hat AI Factory with NVIDIA hardware layer is where the Red Hat and NVIDIA collaboration becomes directly relevant. Red Hat AI Factory with NVIDIA brings together NVIDIA's GPU hardware and the NVIDIA Inference Microservices (NIM) framework with OpenShift AI orchestration and governance capabilities. NIM containers package optimized, validated model configurations that are ready to serve on NVIDIA hardware, and because they run on OpenShift, they inherit the platform's namespace governance, RBAC, and observability stack.
For research institutions that are acquiring NVIDIA GPU infrastructure—which is most of them— the Red Hat AI Factory with NVIDIA reference architecture provides a validated, supported path from hardware to running inference services helping avoid months of integration work. NVIDIA's NIM catalog includes base models across major model families, OpenShift AI's customization pipeline extends those bases with domain-specific fine-tuning. The combination is a practical path from "we have GPUs" to "we have a fine-tuned clinical model serving our researchers."
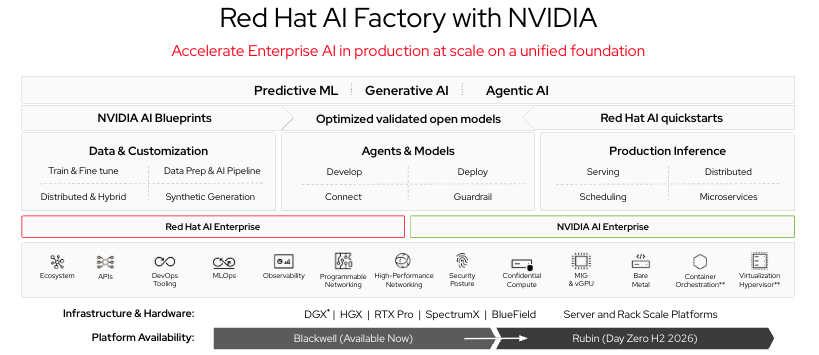
Figure 1: Red Hat AI Factory with NVIDIA
Bridging HPC and cloud-native: The Slinky operator
Slurm powers many of the world's top supercomputers and is the standard interface for HPC job submission at research institutions. Slurm's strengths are real, including exclusive GPU reservations, predictable performance, mature priority queuing, and deep integration with parallel file systems and message passing interface (MPI)-style workloads. The majority of research institutions' HPC users know Slurm, and their pipelines are generally written for Slurm.
The challenge has always been the gap between the Slurm world and the Kubernetes world—2 schedulers, 2 resource accounting systems, 2 ways to request a GPU, 2 operational teams. Data artifacts are moved manually between environments, and GPU capacity often sits idle in the HPC cluster during low-utilization windows while the Kubernetes environment is queuing jobs.
The Slinky operator addresses this gap. As discussed in this article about running Slurm workloads on OpenShift, Slinky is a Kubernetes operator that deploys and manages Slurm components—including slurmctld and slurmd—as containerized workloads inside OpenShift, automating deployment, scaling, and lifecycle management of the Slurm cluster, so it can coexist with Kubernetes-native workloads on the same hardware.
What this means in practice for research platform engineers:
- Unified resource scheduling: Slurm batch jobs and Kubernetes-native AI workloads share the same GPU pool. Idle capacity between large simulation jobs can be allocated to inference or fine-tuning workloads without manual intervention or hardware reassignment.
- Preserved researcher workflows: HPC researchers who submit jobs via sbatch don't have to change their workflow. The Slurm interface they know is still there, but it's also running inside OpenShift now, with all the observability, lifecycle management, and governance that Kubernetes provides.
- Reproducible environments: Slurm jobs run as containers, which means the environment is defined by the container image, and not by whatever happens to be installed on the compute node. This dramatically improves reproducibility and simplifies collaboration between institutions that want to share pipelines.
- Single operational surface: Platform engineers maintain 1 cluster, 1 observability stack, and 1 RBAC model. Slinky doesn't require or create a second infrastructure—it folds HPC scheduling into the platform that's already in use.
NVIDIA's acquisition of SchedMD, the primary developer behind Slurm, signals where this convergence is heading at the industry level. The boundaries between HPC scheduling, Kubernetes orchestration, and AI infrastructure are being intentionally erased. Slinky is Red Hat's contribution to that convergence, available now to run in production.
For a research university operating both an HPC cluster for computational science and an OpenShift environment for AI research, Slinky helps make these 2 investments work as 1.
Models-as-a-Service (MaaS): The shared AI platform model for research institutions
Platform convergence solves the infrastructure problem, but there's another problem that's equally important and less discussed—most research teams do not include infrastructure engineers. A clinical informatics team building a health equity chatbot doesn't want to manage Kubernetes namespaces. A genomics lab that needs a fine-tuned model for variant annotation doesn't want to configure vLLM deployments. A computational social science department that wants to run LLM-based document analysis doesn't want to write Helm charts.
The operational model that solves this is Models-as-a-Service (MaaS).
What is MaaS?
MaaS is an approach where platform engineers deploy, manage, and operate AI models as shared services—exposing them to consumers via APIs,. In a research institution context, this means the research computing platform team operates the GPU cluster, manages the model lifecycle, handles versioning and updates, and maintains the serving infrastructure, while research teams consume model endpoints as a service, the same way they consume a compute allocation or a storage mount.
The implications for research productivity are significant. Consider what the workflow looks like today versus what it looks like under a MaaS model.
Today, without MaaS
A research team needs a fine-tuned model for their project. They spend weeks setting up a GPU environment, installing dependencies, configuring a serving framework, and debugging infrastructure problems. Their actual research begins when the infrastructure finally works, which may be months after the project started. When they're done, the model lives on 1 person's workstation or a temporary cluster allocation that gets reclaimed.
With MaaS on OpenShift AI
The research team brings their dataset and their domain requirements to the platform team. They work with platform engineers to configure and run a fine-tuning job through Training Hub on OpenShift AI. The resulting model is served as a versioned, governed API endpoint on the shared cluster. Other research teams with related needs can access the same endpoint. When the model needs to be updated with new data, the training pipeline is rerun and the new version is promoted through the same governed process.
The platform team takes care of the infrastructure while the research team handles the science. This division of labor helps scale AI capabilities across an institution.

Figure 2: Converging HPC, cloud-native, and Models-as-a-Service for scientific research
For platform engineers, MaaS on OpenShift AI ("Research-as-a-Service," if you you will) provides the operational handles they need—namespace-level resource quotas that prevent any single research project from monopolizing GPU capacity, model versioning through a registry, RBAC that controls who can deploy and who can only consume, and observability across all serving workloads through a unified dashboard.
For research institutions with multiple research groups (e.g. a medical school, a computational biology department, a school of informatics, and a data science institute all running on the same platform) MaaS is how the platform team stays ahead of demand without scaling headcount linearly with the number of research projects.
Data gravity: Bringing AI to where research lives
Research has a data gravity problem. The most valuable datasets (clinical records, genomic sequences, simulation outputs) are already large, distributed, and often immovable due to cost, latency, or governance constraints. Moving petabytes of data to a cloud endpoint is inefficient and often impossible.
The platform we're discussing here brings AI to the data, not the other way around. By running model training, fine-tuning, and inference where data already resides (on-premises, in the lab, in secured research environments, etc.), you can avoid unnecessary data movement while preserving performance and compliance.
When it comes right down to it, this is not just an optimization, it’s really an architectural requirement. The closer the model is to the data, the faster the iteration loop, the lower the cost, and the more practical it becomes to operationalize AI across large-scale research workflows.
Where this architecture applies: Research across sectors
Of course, this platform isn't specific to academic research. The architecture generalizes across any institution where domain expertise matters, data governance constrains cloud-native deployment, and research workloads span the HPC-to-cloud-native spectrum.
- Research universities and Federally funded research and development centers (FFRDCs): Universities and federally funded research and development centers like national laboratories usually have the infrastructure this architecture addresses—HPC clusters for simulation-heavy research, growing cloud-native AI demand from data science groups, and platform engineering teams trying to serve dozens of research groups with different compute requirements.
- Medical institutions and teaching hospitals: Clinical AI is one of the fastest-growing areas of research investment, and it's one of the most demanding in terms of model accuracy, data governance, and safety requirements. General-purpose cloud models are frequently non-starters due to patient data privacy obligations. These organizations need fine-tuned models that run on-premises, with audit logging and access controls, served through a governed institutional platform.
- Defense and intelligence research: FFRDCs and defense contractors operating in classified or controlled environments share the same data governance needs as clinical research, compounded by classification requirements that prohibit the use of cloud APIs. These require on-premises model serving, disconnected operation, and fine-tuned models that carry classified domain knowledge internally.
- Financial services and quantitative research: Research groups in financial services (e.g., quant research, risk modeling, regulatory analysis) work with proprietary data and operate under regulatory constraints that limit what can be sent to external APIs. These need fine-tuned models trained on internal research, served on-premises via MaaS, and accessible through governed APIs that integrate with existing research workflows.
- Energy and industrial research: Oil and gas, utilities, and industrial research organizations run computationally intensive simulation workloads alongside growing ML pipelines for materials research, predictive maintenance, and geophysical analysis. Slinky is particularly relevant in this sector, because Slurm-based simulation workflows are standard and ML-driven analysis is increasingly required downstream of those simulations.
Across all of these contexts, the architectural pattern is consistent: converge HPC and cloud-native scheduling, customize models for domain specificity, serve them efficiently through a shared MaaS platform, and govern access at the institutional level.
Putting it together: What the platform enables
As an example, here's what the full architecture enables for a research institution that has deployed it:
A computational genomics researcher submits a large-scale variant calling job via Slurm, the same way they've submitted HPC jobs for years. The Slinky operator schedules it as a containerized workload on OpenShift, on the same GPU nodes that are also serving fine-tuned inference endpoints. When the job completes, the outputs are stored in a shared object store accessible to both the HPC and Kubernetes environments.
A clinical NLP researcher in the medical school needs a model fine-tuned on de-identified clinical notes for a named entity recognition task. They work with the platform team to run a Low-Rank adaptation (LoRA) fine-tuning job through Training Hub on OpenShift AI, using a base model from the NVIDIA NIM catalog. The resulting model is versioned and served as a MaaS endpoint. 2 other research teams with adjacent NLP tasks immediately start consuming the same endpoint, spreading the fine-tuning cost across the institution.
A cybersecurity research group at an FFRDC needs to analyze threat intelligence reports at scale using an LLM. Because their data carries sensitivity constraints that prohibit cloud API usage, the model runs entirely on-premises on their OpenShift cluster. The model has been fine-tuned on their classified dataset using InstructLab synthetic data generation to augment their small labeled dataset. The endpoint is accessible only to namespaces with the appropriate RBAC bindings.
A platform engineer managing all of these workloads on the same cluster sees a single observability dashboard with GPU utilization across Slurm and Kubernetes workloads, model serving latency by endpoint, training job queue depth, and resource quota utilization by namespace. Resource contention between workloads is resolved by the unified scheduler, not by manual intervention.
Each of these capabilities is available today in the Red Hat AI and OpenShift AI, integrated with NVIDIA hardware through the Red Hat AI Factory with NVIDIA reference architecture, and extended to HPC workflows through the Slinky operator.
Closing thoughts
The researchers who will drive the next generation of discovery are going to use LLMs as a primary tool, as a core part of their research workflow, not as a supplement to their existing methods
What they need from the platform is capability they can use without becoming infrastructure engineers. They need fine-tuned models that actually know their domain, inference that is fast and reliable, HPC workflows that don't require a context switch to a different cluster,and shared access through a governed service.
Together, Red Hat OpenShift, Red Hat AI, NVIDIA, and the Slinky operator can provide that platform.
Resource
Get started with AI for enterprise organizations: A beginner’s guide
About the authors

I build real-world GenAI solutions for organizations that can’t afford to get it wrong.
My career spans national security, enterprise software, and next-generation AI platforms, with more than a decade focused on solving complex problems at the intersection of data, intelligence, and technology. I began in the intelligence community, serving eight years with the NSA and across the IC in intrusion defense, intelligence analysis, and mission-critical cyber operations. That experience in high-stakes security, pattern recognition, and adversarial thinking continues to shape how I approach GenAI strategy and deployment today.
Since then, I’ve led product and platform initiatives in digital ecosystems, advised startups, and worked across the data science landscape helping organizations move from experimentation to production. Much of my work focuses on making generative AI models more knowledgeable and reliable by grounding them in domain-specific data, mission context, and real operational constraints across national security, research, and healthcare.
Today, as an AI Solutions Advisor at Red Hat and IBM, I partner with government agencies, research institutions, and enterprises across North America to design scalable GenAI systems that work in the real world. The goal is never novelty — it’s better decisions, faster execution, and durable advantage.

O'Neill Joseph is a Sr AI Solutions Architect in Red Hat focused on specialized AI deployments, has over 20 experience in IT Infrastructure, from telecommunications to cloud native infrastructure with a Degree in Cybersecurity and IT Networking from University of Maryland.

Working with customers to build IT solutions for over 25 years, Wes has experience integrating various technologies and approaches to produce outcomes and achieve mission objectives. Serving highly regulated industries such as healthcare and defense, Wes understands how to approach IT challenges with a secure, compliant end state in mind.
At Red Hat, Wes focuses on helping customers build cloud-native platforms where they can run AI/ML workloads, integrate heterogeneous data and facilitate outcomes anywhere in the world.
Prior to joining Red Hat, Wes was the CTO at a small technology company in DC helping build solutions for a variety of government customers.
Wes has managed global engineering teams, built services to help customers scale their missions, and designed software solutions to meet the needs of growing organizations.
More like this
Manage MCP servers on Red Hat OpenShift with the MCP lifecycle operator
The same 16 GPUs, twice the users: Inference-aware routing for LLM clusters
Technically Speaking | Build a production-ready AI toolbox
Technically Speaking | Platform engineering for AI agents
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds