
Welcome to the Kubernetes deep dive blog post series. We, that is, Stefan Schimanski (Engineering) and Michael Hausenblas (Advocacy), will dive into specific aspects of Kubernetes and how they’re utilized within OpenShift. If you’re interested in the inner workings of Kubernetes and how to debug it, this blog post series is for you. Also, if you want to extend Kubernetes or start contributing to the project, you might benefit from it. Familiarity with Go is an advantage but not a hard requirement to follow along.
In this installment, we start with a general introduction of the Kubernetes API Server, provide some terminology and explain the API request flow. Future posts will cover storage-related topics and extensibility points of the API Server.
Introducing the API Server
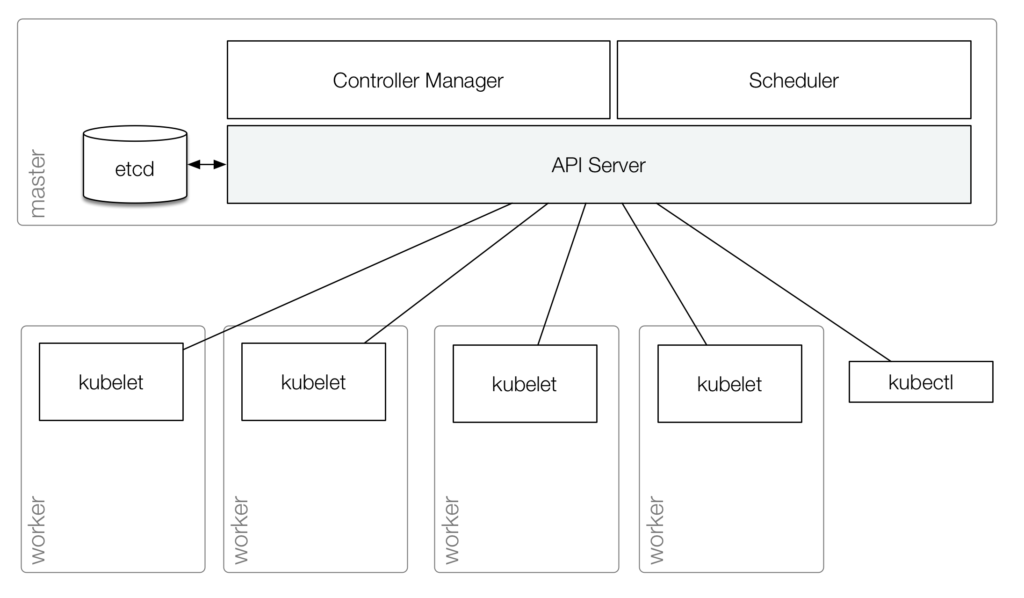
On a conceptual level, Kubernetes is made up of a bunch of nodes with different roles. The control plane on the master node(s) consists of the API Server, the Controller Manager and Scheduler(s). The API Server is the central management entity and the only component that directly talks with the distributed storage component etcd. It provides the following core functionality:
- Serves the Kubernetes API, used cluster-internally by the worker nodes as well as externally by kubectl
- Proxies cluster components such as the Kubernetes UI
- Allows the manipulation of the state of objects, for example pods and services
- Persists the state of objects in a distributed storage (etcd)
The Kubernetes API is a HTTP API with JSON as its primary serialization schema, however it also supports Protocol Buffers, mainly for cluster-internal communication. For extensibility reasons Kubernetes supports multiple API versions at different API paths, such as /api/v1 or /apis/extensions/v1beta1. Different API versions imply different levels of stability and support:
- Alpha level, for example
v1alpha1is disabled by default, support for a feature may be dropped at any time without notice and should only be used in short-lived testing clusters. - Beta level, for example
v2beta3, is enabled by default, means that the code is well tested but the semantics of objects may change in incompatible ways in a subsequent beta or stable release. - Stable level, for example,
v1will appear in released software for many subsequent versions.
Let’s now have a look at how the HTTP API space is constructed. At the top level we distinguish between the core group (everything below /api/v1, for historic reasons under this path and not under /apis/core/v1), the named groups (at path /apis/$NAME/$VERSION) and system-wide entities such as /metrics.
A part of the HTTP API space (based on v1.5) is shown in the following:
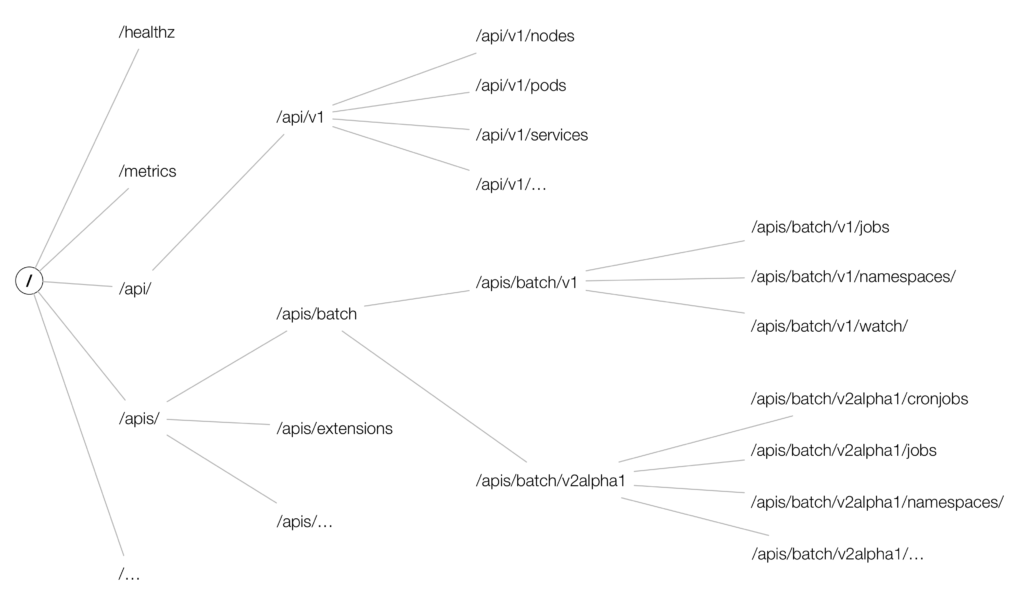
Going forward we’ll be focusing on a concrete example: batch operations. In Kubernetes 1.5, two versions of batch operations exist: /apis/batch/v1 and /apis/batch/v2alpha1, exposing different sets of entities that can be queried and manipulated.
Now we turn our attention to an exemplary interaction with the API (we are using Minishift and the proxy command oc proxy --port=8080 here to get direct access to the API):
$ curl http://127.0.0.1:8080/apis/batch/v1
{
"kind": "APIResourceList",
"apiVersion": "v1",
"groupVersion": "batch/v1",
"resources": [
{
"name": "jobs",
"namespaced": true,
"kind": "Job"
},
{
"name": "jobs/status",
"namespaced": true,
"kind": "Job"
}
]
}
And further, using the new, alpha version:
$ curl http://127.0.0.1:8080/apis/batch/v2alpha1
{
"kind": "APIResourceList",
"apiVersion": "v1",
"groupVersion": "batch/v2alpha1",
"resources": [
{
"name": "cronjobs",
"namespaced": true,
"kind": "CronJob"
},
{
"name": "cronjobs/status",
"namespaced": true,
"kind": "CronJob"
},
{
"name": "jobs",
"namespaced": true,
"kind": "Job"
},
{
"name": "jobs/status",
"namespaced": true,
"kind": "Job"
},
{
"name": "scheduledjobs",
"namespaced": true,
"kind": "ScheduledJob"
},
{
"name": "scheduledjobs/status",
"namespaced": true,
"kind": "ScheduledJob"
}
]
}
In general the Kubernetes API supports create, update, delete, and retrieve operations at the given path via the standard HTTP verbs POST, PUT, DELETE, and GET with JSON as the default payload.
Most API objects make a distinction between the specification of the desired state of the object and the status of the object at the current time. A specification is a complete description of the desired state and is persisted in stable storage.
Terminology
After this brief overview of the API Server and the HTTP API space and its properties, we now define the terms used in this context more formally. Primitives like pods, services, endpoints, deployment, etc. make up the objects of the Kubernetes type universe. We use the following terms:
Kind is the type of an entity. Each object has a field Kind which tells a client—such as kubectl or oc—that it represents, for example, a pod:
apiVersion: v1
kind: Pod
metadata:
name: webserver
spec:
containers:
- name: nginx
image: nginx:1.9
ports:
- containerPort: 80
There are three categories of Kinds:
- Objects represent a persistent entity in the system. An object may have multiple resources that clients can use to perform specific actions. Examples:
PodandNamespace. - Lists are collections of resources of one or more kinds of entities. Lists have a limited set of common metadata. Examples:
PodListsandNodeLists. - Special purpose kinds are for example used for specific actions on objects and for non-persistent entities such as
/bindingor/status, discovery usesAPIGroupandAPIResource, error results useStatus, etc.
API Group is a collection of Kinds that are logically related. For example, all batch objects like Job or ScheduledJob are in the batch API Group.
Version. Each API Group can exist in multiple versions. For example, a group first appears as v1alpha1 and is then promoted to v1beta1 and finally graduates to v1. An object created in one version (e.g. v1beta1) can be retrieved in each of the supported versions (for example as v1). The API server does lossless conversion to return objects in the requested version.
Resource is the representation of a system entity sent or retrieved as JSON via HTTP; can be exposed as an individual resource (such as .../namespaces/default) or collections of resources (like .../jobs).
An API Group, a Version and a Resource (GVR) uniquely defines a HTTP path:

More precisely, the actual path for jobs is /apis/batch/v1/namespaces/$NAMESPACE/jobs because jobs are not a cluster-wide resource, in contrast to, for example, node resources. For brevity, we omit the $NAMESPACE segment of the paths throughout the post.
Note that Kinds may not only exist in different versions, but also in different API Groups simultaneously. For example, Deployment started as an alpha Kind in the extensions group and was eventually promoted to a GA version in its own group apps.k8s.io. Hence, to identify Kinds uniquely you need the API Group, the version and the kind name (GVK).
Request Flow and Processing
Now that we’ve reviewed the terminology used in the Kubernetes API we move on to how API requests are processed. The API lives in k8s.io/pkg/api and handles requests from within the cluster as well as to clients outside of the cluster.
So, what actually happens now when an HTTP request hits the Kubernetes API? On a high level, the following interactions take place:
- The HTTP request is processed by a chain of filters registered in
DefaultBuildHandlerChain()(see config.go) that applies an operation on it (see below for more details on the filters). Either the filter passes and attaches respective infos toctx.RequestInfo, such as authenticated user or returns an appropriate HTTP response code. - Next, the multiplexer (see container.go) routes the HTTP request to the respective handler, depending on the HTTP path.
- The routes (as defined in
routes/*) connect handlers with HTTP paths. - The handler, registered per API Group (see groupversion.go and installer.go) takes the HTTP request and context (like user, rights, etc.) and delivers the requested object from storage.
The complete flow looks as follows:

Again, note that for brevity, we omit the $NAMESPACE segment of the HTTP paths in above figure.
Let’s now have a closer look at the filters that DefaultBuildHandlerChain() in config.go sets up:
WithRequestInfo()as defined in requestinfo.go attaches aRequestInfoto the contextWithMaxInFlightLimit()as defined in maxinflight.go limits the number of in-flight requestsWithTimeoutForNonLongRunningRequests()as defined in timeout.go times out non-long-running requests like mostGET,PUT,POST,DELETErequests in contrast to long-running requests like watches and proxy requestsWithPanicRecovery()as defined in wrap.go wraps an handler to recover and log panicsWithCORS()as defined in cors.go provides a CORS implementation; CORS stands for Cross-Origin Resource Sharing and is a mechanism that allows JavaScript embedded in a HTML page to make XMLHttpRequests to a domain different from the one the JavaScript originated from.WithAuthentication()as defined in authentication.go tries to authenticate the given request as a user and stores the user info in the provided context. On success, theAuthorizationHTTP header is removed from the request.WithAudit()as defined in audit.go decorates the handler with audit logging information for all incoming requests The audit log entries contain infos such as source IP of the request, user invoking the operation, and namespace of the request.WithImpersonation()as defined in impersonation.go handles user impersonation, by checking requests that attempt to change the user (similar to sudo).WithAuthorization()as defined in authorization.go passes all authorized requests on to multiplexer which dispatched the request to the right handler, and returns a forbidden error otherwise.
And with this, we conclude this first installment of the API Server deep dive. Next time we’ll have a look closer look at how serialization of resources is happening as well as how objects are persisted in the distributed storage.
About the authors
More like this
Why Operational Resilience and Digital Sovereignty Top the CIO Agenda
How Red Hat OpenShift 4.22 impacts enterprise AI’s bottom line
Edge computing covered and diced | Technically Speaking
Crack the Cloud_Open | Command Line Heroes
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds