
This week OpenShift raised the bar on what you should expect from a cloud ready container platform. With the release of OpenShift Enterprise 3.2, the product is able to advance developer experience, scale, and operational experience. Built on Kubernetes 1.2.x and docker 1.9.x, this release of OpenShift benefits from the innovations coming from two of the most vibrant container and orchestration communities in open source today. OpenShift contributes to those communities and adds to them an experience that understands a large variety of runtime and application frameworks while offering the freedom to pursue any application architecture that makes sense for the business task at hand.
Specifically for the OpenShift Enterprise 3.2 release, we have worked on features that allow a user of the platform to do more powerful things while having to know less about the platform administrator. Which means the platform administrator has been given more tools to predefine that user's experience without the user knowing. Most of the features fall into three buckets:
- User Experience
- Build Automation and Application Deployment
- Resource Management and Platform Control
User Experience
An OpenShift user has received some great updates lately. If you have not had a chance to check out the OpenShift 3.1.1 errata release, we did sneak some updates in there for you in addition to some new ones in OpenShift 3.2. You will want to check out the following cool UX upgrades.
Now you can edit yaml directly from the webconsole should you be doing some more advanced deployments. This cuts down on the need to flip back and forth between command line and webconsole.
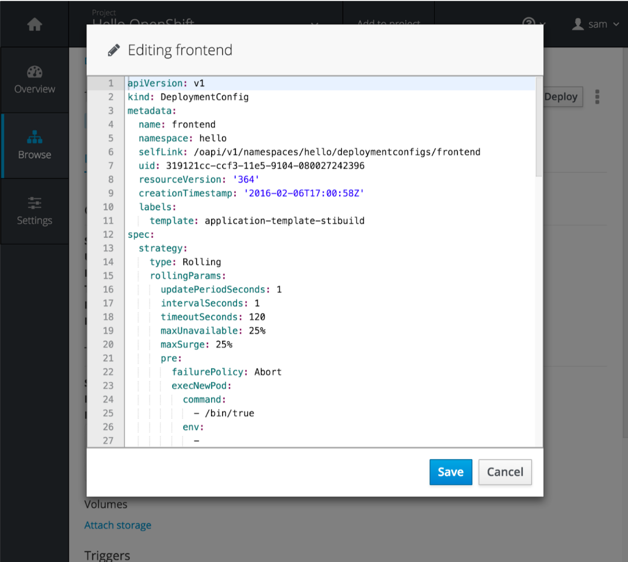
Rather than only working with routes on the command line, you can now edit them from the webconsole experience.

Users can interact more granularly with their build configuration from the webconsole. You could always declare the source git url for an application and set the webhook for automatic rebuilds if a git commit had occurred, but now from the webconsole you can more easily declare repository ref and context directories for git. You can more granularly select image streams and tags at time of deployment as a user. You can declare build time environmental variables. And now, just like you can set the watch to automatically re-build and re-deploy your application on a code change, with a click of a button you can have OpenShift watch for builder image changes and build configuration changes. This is a fantastic feature!

As OpenShift's builder policies free you to become more automated and continuous with your applications across their life cycle, you will find the ability to look back at all the builds for a specific application to be highly valuable.
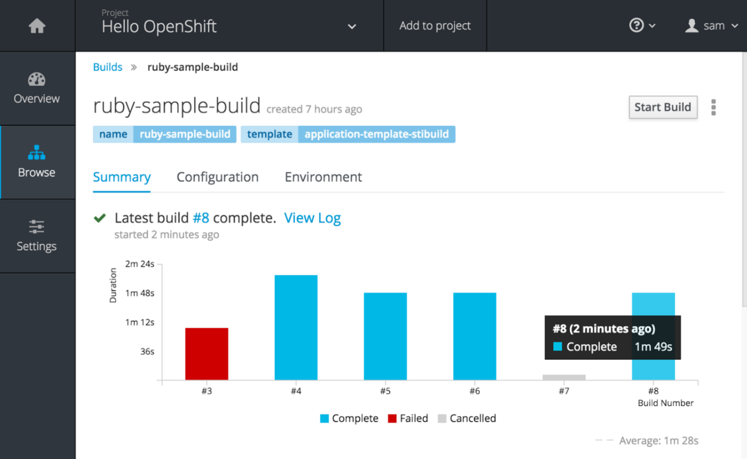
Although most users will select application templates with storage needs already declared in them, you can now attach remote persistent storage volumes from the webconsole instead of only the command line. OpenShift has been providing persistent storage for stateful applications running in docker containers for almost a year now. The webconsole will not only allow you to attach/de-attach storage, it will also list and summarize your existing storage claims.

End users now have an ability to change application resources should their platform administrator allow them. Still living under the CPU and MEM constraints of their project, users can select specific pods and allocate them more or less CPU/MEM resources.

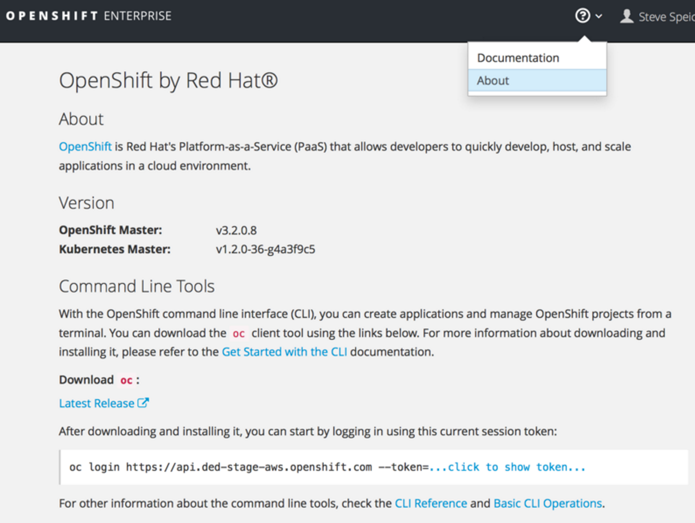
On-boarding completely new users has been made even easier through a new "about" screen on the webconsole that allows a user to download the go client "oc" command line locally to their laptop while also showing them the specific token they will need to supply to the "oc" command line in order to login.
Build Automation and Application Deployment
One of the most beloved features in OpenShift 3 is the ability to set policy that will control whether or not your application is re-built and re-deployed when the base layer of the application is updated. Users have enjoyed this feature for applications that were provisioned from source code since OpenShift 3.0. For binary deployments of artifacts into applications, we had not offered this value add. OpenShift 3.2 removes that limitation and brings binary builds on par with source builds.
![]()
People love the ability to maintain sensitive information on the platform as a secret. Until now, secrets were primarily used during user administration and providing information for applications running in pods. OpenShift 3.2 offers an ability to use that same secret concept during builds and assembly.
As users begin learning more and more about the Source-To-Image (S2I) assembly process in OpenShift 3.0 and 3.1, they began wanting to store more of the objects they used during the construction of their applications in the OpenShift registry. For example, if your application required a library, such as a jdbc driver, it would be nice to maintain that object in the OpenShift registry rather than your github repo. OpenShift 3.2 delivers that ability and more. Now, not only can you store the object in the registry, but you can also leverage policy to automatically re-build and re-deploy your application should there be an update to the object. You can insert new checkpoints in the automation sequence to run tests before the image push. Should you decide to clean up configuration, we will now remove the builds related to that configuration. All and all, great improvements across the board for OpenShift builds.
We delivered Jenkins as a container for users to deploy within their projects in OpenShift 3.1. Now in OpenShift 3.2, we have taken that image and enhanced it with modules and knowledge of OpenShift. The Jenkins now comes out of the box with pre- and post- modules that are oriented to allowing Jenkins to spawn slave builders on OpenShift that call OpenShift Source-To-Image and deployment APIs. Now a user can take advantage of smoke, functional, and performance testing abilities found in Jenkins automation hooks while still using the OpenShift builder and/or deployment functions. There is a great level of choice over how you design your Jenkins pipeline.
Later this month the RHEL Software Collections will update OpenShift runtime and application framework versions. We see some significant version improvements for node.js and mongoDB. OpenShift offers the ability to run any docker or open container compliant image. What is special about a Software Collection's docker image is that Red Hat maintains them for you. We watch over them for CVEs and bug fixes and we update them on the Red Hat registry on a continuous basis. Based on your application build policies, you can have OpenShift automatically re-build and re-deploy any application that is using one of these base image. It is what's inside the container that counts and OpenShift allows you to unload some of your cost of ownership over to Red Hat by letting you get the most out of your support subscription.

Across the coming months of May and June, you will see amazing new versions flowing out of the JBoss team onto the OpenShift platform. EAP, A-MQ, BPM, BRMS, and Red Hat SSO IDM solutions all have exciting new features they will be enabling on the OpenShift platform for next generation application services.
Developers and operators have a new way to inject configuration into their application services. Until now, most of an application's configuration was baked into the github, assembly scripts, or pod specification. That ultimately means we are connecting configuration with code. With a new feature called configMap, we can declare configuration much in the same way we declare secrets. Configuration can be command line arguments we would have mentioned in a pod specification, or environmental variables for application component configuration, or even entire .conf or .properties files. We can mount these configMaps into the container via a volume mount and if you change the configuration outside of the pod in the mount, you can effect the running pod. We can start to do some fairly powerful things with this feature.
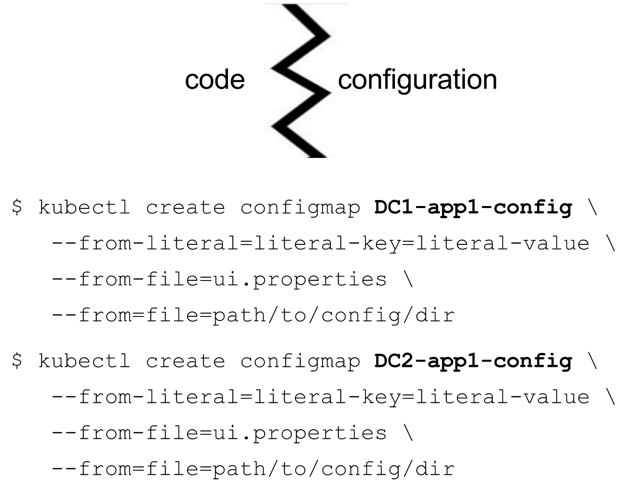
The registry got smarter in OpenShift 3.2. You now have control over when it will look out to internal or other network docker registries instead of using a cron process. Previously, administrators had to script an 'oc import-image' command. Now we control it via a imagePolicyConfig definition on the master. The default is every 15 mins.

Resource Management and Platform Control
As more and more diverse workloads are run on OpenShift, platform administrators will need ways to allow users to voice resource strategies. Users will want workloads to have different priorities against each other. For awhile now, OpenShift has had three resource scheduling guarantees. New in OpenShift 3.2 is an ability to set a limit quota where in the past the quota was only available on the resource request. The OpenShift scheduler has also been made more intelligent to honor the allocatable resources on a node (subtracts out the reserved) instead of total available CPU and MEM on a node. Given the new ability to quota on limits, platform administrators can force users into strategies that increase their overall experience on the platform.

Everyone wants to mix stateful and stateless services on a single platform. This requires remote persistent storage due to the ephemeral nature of containers. The problem with storage is that it comes from a IaaS layer that we are trying to abstract away from the application. A popular nuance of storage is the fact it could be provided in one area of the datacenter, say for example an availability zone, and once you start consuming it in that location you are then not allowed to move to a totally different availability zone; be that with a new instance of the application or a restart of an existing application instance. The solution to this problem requires placement policy to be made aware of the storage boundaries. OpenShift 3.2 has made this enhancement. It allows users to receive the correct storage without losing the ability to ask for random storage as a tenant. We also added an ability for the scheduler to understand that a node is consuming 78 EBS volumes and to not attempt to allocate another pod to that node.

We have introduced a way to allow transient or short lived tasks on the platform to be charged against a different quota than the ones that are user facing and displayed in the project such as CPU, MEM, number of PV, number of pods, number of replication controllers, and number of services. By declaring pods with an activeDeadlineSeconds definition, we can treat them as "run once" pods. Specifically for OpenShift, this means that users do not have to spend their quota on builds and deployer pods.

Another great feature is the introduction of the Daemon Set controller. Platform administrators have a need to run software such as backup utilities and monitoring agents across all nodes now and into the future. Before Daemon Set people would bake such pods into the node's init scripts. Unfortunately, that doesn't allow the pod to take advantage of the health checks and scaling abilities found on the platform. With Daemon Set you can target all node of a certain label. You can change a label on a node to something of interest and Daemon Set will target it. It can perform that placement without the scheduler so you can leverage the feature before the master is even active. You can leverage hostPorts and access node IP for management tasks.

In OpenShift 3.2 the kublet and docker daemon that run on each node have a much more efficient relationship. We have moved them to a event polling generation method of communication (known as PLEG). This has allowed us to now support 110 pods per node. That is a 2.5X improvement over previous releases. At the same time, we recognize a 4X improvement in CPU and MEM consumption on the node. Plus, we have changed to using a parallel docker pull design by default. With those two improvements, we have a much more efficient platform.
Platform administrators have always had an ability to setup a project template for users. The project template is a way to insure you are enforcing resource consumption quota, content control, and nodeSelection while still letting the user create additional projects. In OpenShift 3.2 we add the ability to label the users and further control how many projects they are allowed to have. This new configuration is found on the master via the ProjectRequestLimitConfig plugin to the admission controller.

When a user forgets to claim a remote persistent storage volume for an application they expect to write out to local file systems and that can get messy. Containers that are writing locally do so knowing that information will get blown away when the pod restarts, but until that time they can fill up the file systems. Pods will write such information to /var/lib/origin/openshift.local.volumes. With OpenShift 3.2, we now have a way to quota such writing to stop users from accidentally filling up a node's file systems and effecting other users. This is controlled in the node's node-config.yaml file with a new volumeConfig section.
Speaking of storage, we have enhanced our user experience with storage providers that allow for metadata tagging. For example, on AWS EBS we will now automatically annotate the name of the volume in OpenShift to the EC2 EBS metadata tag. This gives a platform administrator the ability to log into EC2 and see information on the EBS volumes that will help them connect their infrastructure to the applications using them. Since we are talking about block storage, we add a default behavior to fsck all mounts before persistent volumes are added into applications. Lastly, we improved the NoDiskConflicts scheduler placement rule for CEPH RBD to be able to observe if a CEPH volume is already mounted to a node so that double mounting does not occur.
Keeping the OpenShift platform up to date got easier in OpenShift 3.2. Our ansible installer can now takes a openshift_rolling_restart_mode setting that will tell OpenShift that you want it to figure out the HA master layout and roll an update across them as to not take downtime on the master layer of the product.
Conclusion
My conclusion to you is simple. I honestly don't know of another open container platform that is as ready as OpenShift for enterprise or public cloud levels of consumption. The Kubernetes eco-system is producing some of the most precise and feature rich orchestration abilities I've seen in a while. All aspects of the Linux market spanning both on premise and public cloud have embraced the linux container movement. OpenShift has been able to act has a magnify glass to focus those technologies in on a DevOps problem to accelerate application services to production. There is no one even close to designing for the code, artifact, and docker layering ability while templating for application architectures that span traditional tiered stacks and organic microservices. All from a platform that can span public and private cloud providers. Welcome to OpenShift 3.2.
About the author

Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges

Original shows
Entertaining stories from the makers and leaders in enterprise tech
Products
- Red Hat Enterprise Linux
- Red Hat OpenShift
- Red Hat Ansible Automation Platform
- Cloud services
- See all products
Tools
- Training and certification
- My account
- Customer support
- Developer resources
- Find a partner
- Red Hat Ecosystem Catalog
- Red Hat value calculator
- Documentation
Try, buy, & sell
Communicate
About Red Hat
We’re the world’s leading provider of enterprise open source solutions—including Linux, cloud, container, and Kubernetes. We deliver hardened solutions that make it easier for enterprises to work across platforms and environments, from the core datacenter to the network edge.
Select a language
Red Hat legal and privacy links
- About Red Hat
- Jobs
- Events
- Locations
- Contact Red Hat
- Red Hat Blog
- Diversity, equity, and inclusion
- Cool Stuff Store
- Red Hat Summit