
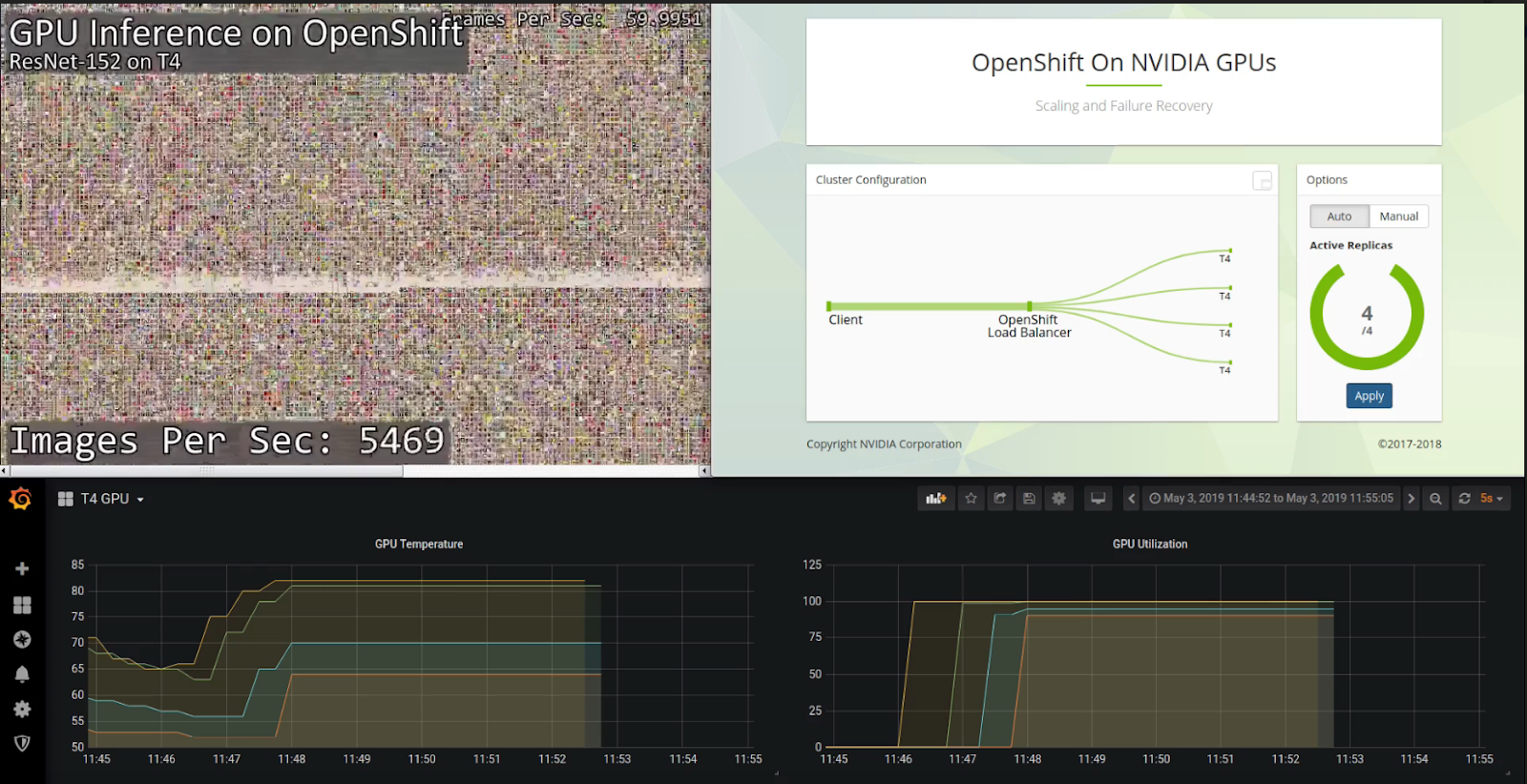
Running the Flowers demo on OpenShift with NFD and SRO
Introduction
Managing hardware accelerator cards like GPUs or high-performance NICs in Kubernetes is hard. The special payload (driver, device-plugin, monitoring stack deployment and advanced feature discovery), updates and upgrades, are tedious and error-prone tasks, and often third-party vendor knowledge is needed to accomplish these steps.
The Special Resource Operator (SRO) is a template for exposing and managing accelerator cards in a Kubernetes cluster. It handles the hardware seamlessly from bootstrapping to update and upgrades fully managed.
The first part will describe the SRO in general where the second part will describe the building blocks in SRO and how to enable a different hardware accelerator step by step.
The Benefits of the Special Resource Operator
The SRO template can be applied to "any" hardware accelerator. It does not matter if its a GPU, Network NIC, or FPGA there are similar steps involved when such a hardware accelerator is going to be used in Kubernetes.
Leveraging the Node Feature Discovery project the SRO knows where to deploy the specific hardware stack, meaning only nodes that are labelled correctly receive the special payload (hardware enablement stack).
The first step is to deploy the DriverContainer; the benefit of a DriverContainer is that it can be used on immutable and mutable operating systems. The SRO validates each important step. The DriverContainer ships a configurable container runtime prestart hook for this specific hardware for container enablement.
After successful validation, SRO deploys the device-plugin for exposing the hardware to the cluster and again validates the deployment.
The last step is to deploy monitoring, registering a new special node-exporter and custom Grafana dashboard with Prometheus alerting rules.
Having the custom drivers loaded we can now extract sophisticated information about the hardware with a sidecar container for feature discovery.
Besides the enablement of the specific hardware, the SRO allows the nodes to be soft or hard partitioned via priority-classes or taints and tolerations.
To complete the picture, SRO handles updates and upgrades seamlessly and gracefully. The steps above are not unique to specific hardware; it is a generic way for enabling and exposing hardware in a Kubernetes cluster.
The SRO template is already used as an example implementation for GPUs (https://github.com/nvidia/gpu-operator) and Network NICs (https://blog.openshift.com/launching-openshift-kubernetes-support-for-solarflare-cloud-onload).
Inner Working of the Special Resource Operator
The special resource operator is an orchestrator for resources in a cluster specifically designed for resources that need extra management. This reference implementation shows how GPUs can be deployed on a Kubernetes/OpenShift cluster.
Bootstrap Heterogeneity
There is a general problem when trying to configure a cluster with a special resource. One does not know which node has a special resource or not. To circumvent this bootstrap problem, the SRO relies on the NFD operator and its node feature discovery capabilities. NFD will label the host with node-specific attributes, like PCI cards, kernel or OS version and many more, see (Upstream NFD) for more info.
Here is a sample excerpt of NFD labels that are applied to the node.
Name: ip-xx-x-xxx-xx
Roles: worker
Labels: beta.kubernetes.io/arch=amd64
beta.kubernetes.io/instance-type=g3.4xlarge
beta.kubernetes.io/os=linux
...
feature.node.kubernetes.io/cpuid-AVX=true
feature.node.kubernetes.io/cpuid-AVX2=true
feature.node.kubernetes.io/kernel-version.full=3.10.0-957.1.3.el7.x86_64
...
feature.node.kubernetes.io/pci-10de.present=true
feature.node.kubernetes.io/system-os_release.VERSION_ID=4.0
Node Feature Discovery (NFD) uses a client-server model to label the nodes. Only the NFD-master, running on the master, are able to label. Labeling is a high privilege operation and workloads running on the workers shouldn't have this ability. It is a security measure to prevent workers from labelling themselves as masters and overtaking the system.
The NFD master and worker establish a TLS encrypted gRPC connection to exchange a protocol buffer (a mechanism to serialize structured data) between them. The exchanged data is a map with some metadata (see e.g. labeler.proto of NFD).
Operation Breakdown
The special resource operator implements a simple state machine, where each state has a validation step. The validation step for each state is different and relies on the functionality to be tested of the previous state.
The following descriptions of the states will describe how e.g. the SRO handles GPUs in a cluster.
General State Breakdown
Assets like ServiceAccount, RBAC, DaemonSet, ConfigMap manifests for each state are saved in a ConfigMap and mounted into the container under /etc/kubernetes/special-resource/. One file per state.
The SRO will take each of these assets and assign a control function to each of them. Those control functions have hooks (callbacks) for preprocessing the yaml files or hooks to preprocess the decoded API runtime objects. Those hooks are used to add runtime information from the cluster like kernel-version, and nodeSelectors based on the discovered hardware etc. The callbacks are triggered by annotations of the resource to be created.
After the assets were decoded preprocessed and transformed into API runtime objects, the control functions take care of CRUD operations on those.
The SRO is easily extended just by creating another specialized ConfigMap with the assets that this new special resource needs.

State BuildConfig
The first state of SRO will build a DriverContainer. What a DriverContainer is and how to build it in the right way can be read on the following blog post: How to use entitled image builds to build DriverContainers with UBI
Using entitled builds guarantees that the build always uses the right packages from a trusted source where all the latest security patches are applied and bugs are fixed.
The resulting container image is pushed to the internal registry and is only accessible by the objects in that very namespace, namely the GPU operator and DaemonSets that are using this image in that namespace.
We use a BuildConfig for our DriverContainer builds because BuildConfigs support different triggers on which the build is reinitiated. In the case of SRO we are using the ConfigChange and ImageChange trigger to rebuild the drivers (see https://docs.openshift.com/container-platform/4.3/builds/understanding-image-builds.html for more information).
See section Upgrades for more information on how we are leveraging OpenShift features to make updates seamless and easy.
State Driver
This state will deploy a DaemonSet with a DriverContainer. The DriverContainer holds all userspace and kernel space parts to make the special resource (GPU) work. It will configure the host and tell cri-o where to look for the GPU prestart hook (upstream nvidia-driver-container).
The DaemonSet will use the PCI label from NFD to schedule the DaemonSet only on nodes that have a special resource (e.g. 0x10DE is the PCI vendor id for NVIDIA).
$ nodeSelector:
feature.node.kubernetes.io/pci-10de.present: "true"
To schedule the correct version of the compiled kernel modules, the operator will fetch the kernel-version label from the special resource nodes and preprocess the driver container DaemonSet in such a way that the nodeSelector and the pulled image have the kernel-version in their name:
nodeSelector:
feature.node.kubernetes.io/pci-10de.present: "true"
feature.node.kubernetes.io/kernel-version.full: "KERNEL_FULL_VERSION"
- image: <image-registry>/<namespace>/<image>-KERNEL_FULL_VERSION
This way one can be sure that only the correct driver version is scheduled on the node with that specific kernel-version.
If there is no prebuild DriverContainer available the SRO will use the in the previous step build DriverContainer from the internal registry.
Preferably one wants to use pre build DriverContainer that went through a CI and were tested. The internal build can/should be only a fallback.
State Runtime Hook
The first step in enabling an accelerator in OpenShift/Kubernetes is to enable the hardware in the container. The OCI runtime spec describes hooks that are used for configuring custom actions related to the lifecycle of the container.
For GPUs we are using the nvidia-container-toolkit which is a prestart hook that bind mounts devices, user-space libraries, binaries and configurations from the host into the container. Since the user-space and kernel-space have a tight coupling, this way one can guarantee that the installed user and kernel-space versions are in sync.
The prestart hook delivers all base bits that are needed to enable the hardware in the container. There is no need to install hardware specific parts into the container.
For other hardware we have developed the oci-decorator (https://github.com/openshift-psap/oci-decorator) a generic prestart hook that has a textual configuration file that dictates which devices, libraries and binaries have to be make available in the container. The config file has additionally an activation flag (an environment variable exported in the container) by which the prestart hook is triggered. See e.g. https://raw.githubusercontent.com/openshift-psap/oci-decorator/master/oci-onload.json for a sample configuration on how to enable SolarFlare Onload devices.
State Driver Validation
To check if the driver and the hook are correctly deployed, the operator will schedule a simple GPU workload and check if the Pod status is Success, which means the application returned successfully without an error. The GPU workload will exit with an error, if the driver or the userspace part are not working correctly. This Pod will not allocate an extended resource, only checking if the GPU is working.
State Device Plugin
As the name already suggests, this state will deploy a special resource DevicePlugin with all its dependencies, see state-device-plugin for a complete list. The DevicePlugin is the part that exposes the hardware as an Extended Resource to the cluster, which in turn can be allocated by a Pod.
State Device Plugin Validation
One will use the same GPU workload as before for validation but this time the Pod will request an extended resource (1) to check if the DevicePlugin has correctly advertised the GPUs to the cluster and (2) to check if userspace and kernel space are working correctly.
State Monitoring
This state uses a custom metrics exporter DaemonSet to export metrics for Prometheus. A ServiceMonitor adds this exporter as a new scrape target to the OpenShift monitoring stack.
Besides the enabling of the monitoring stack, SRO will also deploy predefined GPU PrometheusRules to monitor e.g. GPU temperature and fatal failures that are reported by the node exporter.
State Feature Discovery
After deploying the enablement stack, which includes the driver, one can now extract or detect special features about the underlying special resource and use a side-car container for NFD to publish those features with an own prefix (namespace). In the case of the GPU, SRO will use: https://github.com/NVIDIA/gpu-feature-discovery to publish those features. Here is a sample output when describing a Node:
nvidia.com/cuda.driver.major=430
nvidia.com/cuda.driver.minor=34
nvidia.com/cuda.driver.rev=
nvidia.com/cuda.runtime.major=10
nvidia.com/cuda.runtime.minor=1
nvidia.com/gfd.timestamp=1566846697
nvidia.com/gpu.compute.major=7
nvidia.com/gpu.compute.minor=0
nvidia.com/gpu.family=undefined
nvidia.com/gpu.machine=HVM-domU
nvidia.com/gpu.memory=16160
nvidia.com/gpu.product=Tesla-V100-SXM2-16GB
Those labels can be used for advanced scheduling decisions. If workloads need specific compute capabilities they can be deployed to the right node with the fitting GPU.
State Grafana
The last step involves deploying a mutable Grafana instance with a preinstalled GPU dashboard. The following command will show the URL for the Grafana instance.
<span>$ oc get route -n openshift-sro</span>
In the future we might have a mutable Grafana instance that can be extended with custom Grafana dashboards and there will not be a need to deploy an own instance.
Hard and Soft Partitioning
The operator has example CR's how to create a hard or soft partitioning scheme for the worker nodes where one has special resources. Hard partitioning is realized with taints and tolerations where soft partitioning is priority and preemption.
Hard Partitioning
If one wants to repel Pods from nodes that have special resources without the corresponding toleration, the following CR can be used to instantiate the operator with taints for the nodes: sro_cr_sched_taints_tolerations.yaml. The CR accepts an array of taints.
The nvidia.com/gpu is an extended resource, which is exposed by the DevicePlugin, there is no need to add a toleration to Pods that request extended resources. The ExtendedResourcesAdmissionController will add a toleration to each Pod that tries to allocate an extended resource on a node with the corresponding taint.
A Pod that does not request an extended resource e.g. a CPU only Pod will be repelled from the node. The taint will make sure that only special resource workloads are deployed to those specific nodes.
Soft Partitioning
Compared to the hard partitioning scheme with taints, soft partitioning will allow any Pod on the node but will preempt low priority Pods with high priority Pods. High priority Pods could be with special resource workloads and low priority CPU only Pods. The following CR can be used to instantiate the operator with priority and preemption: sro_cr_sched_priority_preemption.yaml. The CR accepts an array of priorityclasses, here the operator creates two classes, namely: gpu-high-priority and gpu-low-priority.
One can use the low priority class to keep the node busy and as soon as a high priority class Pod is created that allocates a extended resource, the scheduler will try to preempt the low priority Pod to make scheduling of the pending Pod possible.
Scale Up and Scale Down
Since the SRO is using DaemonSets as the building block for each of the stages we need to take special care in the scale-up phase. Scale down has not to be considered since the DaemonSet will be scaled down to the correct number of Pods able to run on the nodes.
For scale-up and synchronicity, the SRO uses labels to expose the readiness of the state to the cluster. Each important state will label the special resource node with a label signalling that the state is finished. The dependent states are using Pod affinity and anti-affinity to start execution. If the state is not ready the Pods are repelled. As soon as the state becomes available the DaemonSet will schedule the Pods that satisfy the affinities.
Using labels and affinities to steer the scheduling makes it easy to implement state parallelism. Taking e.g. the state monitoring and feature discovery they are dependent on the device plugin state and hence can be executed in parallel afterwards. Both states have the affinity on the device-plugin state label and as soon as the device-plugin finishes both states are executed simultaneously.
Extensibility of SRO
Each state of the SRO is a file created from a ConfigMap with manifests that belong to this state and need to be created by SRO. By using the Unstructured API we can create any object/resource that is supported by the Kubernetes/OpenShift API.
To add support for another accelerator one has to create a new ConfigMap with a specific name, with the new states and SRO will take those and execute them one by one as described above. The manifests have to adhere to some rules but the existing can be taken as a template. The next part will go into detail on how to enable another accelerator.
Special Resource Driver Updates
Initially, the NFD operator labels the host with the kernel version (e.g. 4.1.2). The SRO reads this kernel version and creates a DaemonSet with a NodeSelector targeting this kernel version and a corresponding image to pull. With the pci-10de label, the DriverContainer will only land on GPU nodes.
This way we ensure that an image is pulled and placed only on the node where the kernel matches. It is the responsibility of the DriverContainer image builder to name the image the correct way, preferably in a CI system.

Updates in OpenShift
Updates in OpenShift can happen in two ways: (1) Only the payload (operators and needed parts on top of the OS) is updated, (2) The payload and the OS are simultaneously updated.
The first case is "easy" the new version of the operator will reconcile the expected state and verify that all parts of the special resource stack are working and then "do" nothing.
The second case is more interesting but technically also uncomplicated, the new operator will reconcile the expected state and see that there is a mismatch regarding the kernel version of the DriverContainer and the updated Node. SRO will try to pull the new image with the correct kernel version. If the correct DriverContainer cannot be pulled, SRO will update the BuildConfig with the right kernel version and OpenShift will reinitiate the build since we have the ConfigChange trigger as described above.
Besides the ConfigChange trigger, we also added the ImageChange trigger, which is important when the base image is updated due to CVE or other bugfixes. For this to happen automatically we are leveraging ImageStreams of OpenShift, an ImageStream is a collection of tags that gets automatically updated with the latest tags. It is like a container repository that represents a virtual view of related images.
To be always up to date another possibility would be to register a github/gitlab webhook so every time the DriverContainer code changes a new container could be built. One has just to make sure that the webhook is triggered on a specific release branch, it is not advisable to monitor a fast moving branch (e.g. master) this would trigger frequent builds.
Stay tuned for part two on how to enable your own accelerator with SRO building blocks. We are going into details and how custom enablement pipelines can be built.
Last but not least here are two videos of NFD and SRO in action:
About the author
More like this
Supercharge RHEL troubleshooting with agentic AI: Introducing goose
Can't patch fast enough? Zero trust as a last line of defense
Technically Speaking | Inside open source AI strategy
Technically Speaking | Build a production-ready AI toolbox
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds