- Introduction
- Challenges
- Prerequisites
- Objective
- Grafana, Cluster Fires, and not Enough Time
- Default Alerting Rules in Observability
- Warnings, Recommendations, and PolicyReports
- Creating Custom Rules within Observability
- Configuring the Alertmanager Receiver to Forward Cluster Alerts, Warnings, or Recommendations to Target Application
- Viewing Generated Default and Custom Alerts from Observability
- Results
- Conclusion
Introduction
In Red Hat Advanced Cluster Management (RHACM) 2.3, the idea of alerting on the policy reports that are generated directly within the hub cluster, and expanded to forward alerts from the managed hub cluster to the Alertmanager. Within RHACM 2.4, the need for alerting has improved and provided users with the capabilities to better manage and reinforce the way users can monitor and interact with their cluster environment through RHACM Observability.
Challenges
This blog post addresses how the end-user can connect to RHACM observability and view their cluster alerts, warnings, and recommendations within an aggregated and centralized overview.
Prerequisites
Objective
Grafana, Cluster Fires, and not Enough Time
With Grafana being a cross-platform open source, analytical, and visual tool, users are able to surveil their cluster health and performance while logged into the RHACM console. When a user deploys RHACM observability on the hub cluster, the user has access to Grafana and can view cluster insights and begin to optimize their managed clusters. To review the Grafana dashboards, the user is required to remain logged into the cluster environment and urged to observe multiple dashboards to be up-to-date on the cluster performance. By constantly monitoring the potential environmental fires, the user is required to spend more time debugging and understanding the cluster metrics. A question arises when the user does not have the availability or time to keep track of the essential dashboard. How can the user be alerted or view the cluster performance within a centralized space? Can the user view the cluster data externally, or outside of the hub cluster console?
For example, what happens when the user is forced to move away from their computer or cannot access their cluster environment? During a crucial working period, the cluster performance begins to drastically decline, there's a high possibility that the user is unaware of the issue since they are not monitoring Grafana (or any other applications that require them to be logged into the hub cluster console).
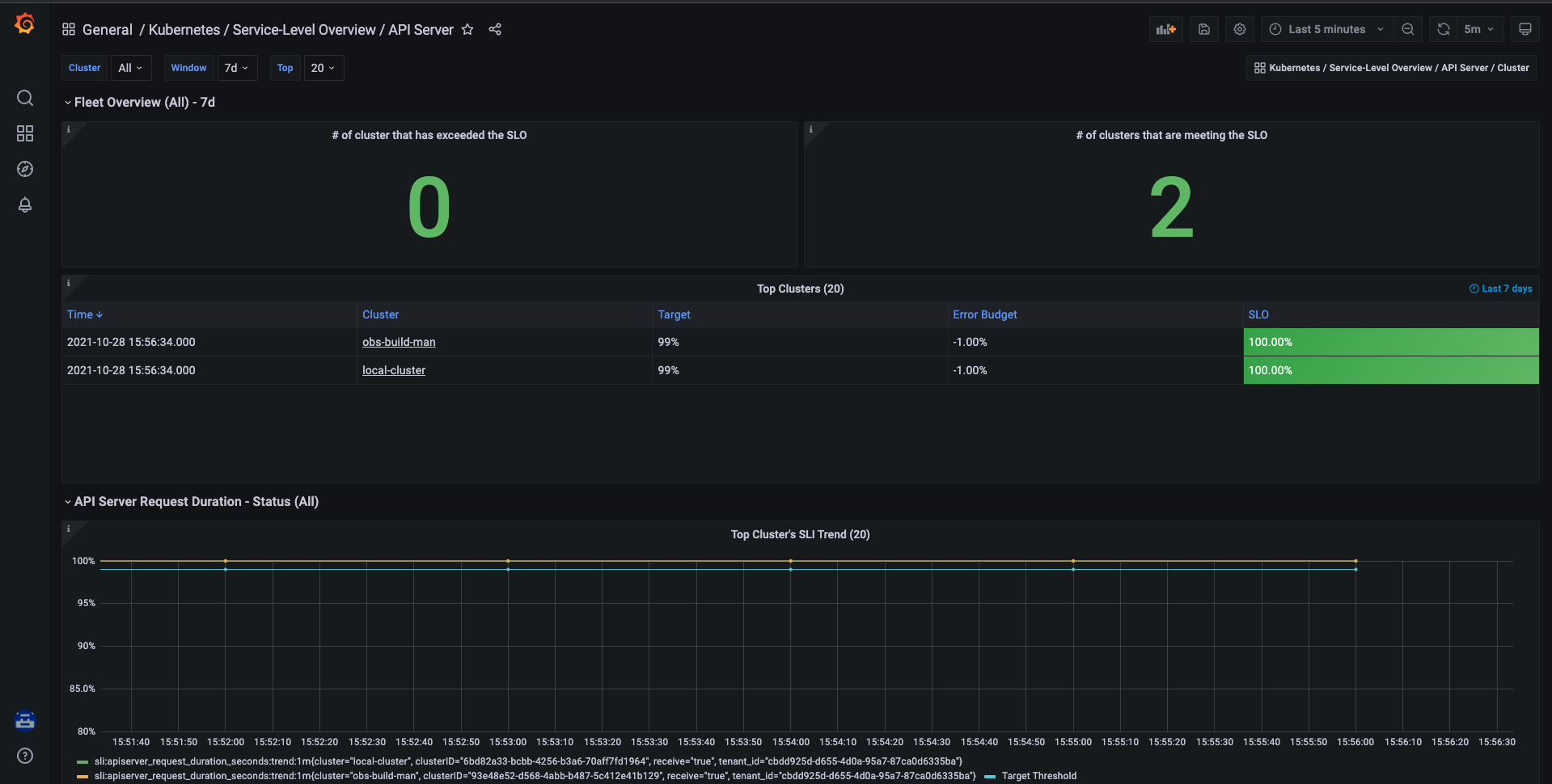
Fig. 1 - Monitoring service-level overview for Kubernetes API server.
The issue occurs when the user has to move away or shift their focus from the Grafana dashboard to another subject of interest. Without constantly monitoring the dashboard, the user loses more awareness of the cluster health and performance until they are able to reconcentrate on the targeted dashboard. Not only is this time consuming for the user, it also decreases productivity at a higher cost.
RHACM observability provides a solution to lessen the continual demand of observing individual Grafana dashboards, so that end-users have more time to increase their productiveness. Through RHACM, observability provides out-of-the-box alerting rules and policy reports for the user to analyze and gain a straightforward understanding of the cluster condition. Rather than viewing multiple pages within the RHACM console, use observability to forward critical alerts or recommended reports to a centralized area for the data to be reviewed. By removing the sizeable dependency on Grafana, the total time consumed when watching the dashboards is reduced; the user can be a step ahead of the curve before they experience interruptions within their cluster.
Default Alerting Rules in Observability
By default, RHACM observability supports out-of-the-box alerting rules that can be viewed within Grafana. If the user navigates to the Explore page within Grafana and enters a query for the ALERTS metrics, they can view pending or active alerts within the hub cluster, along with the alerts from all managed cluster environments. Users must be cognizant that the ALERTS metric is only available if the alert rule is evaluated as true. The alerting rules are defined in the thanos-ruler-default-rules ConfigMap in the open-cluster-management-observability namespace; however, the ConfigMap only contains alert rules for the local-cluster.
Warnings, Recommendations, and PolicyReports
Introduced in RHACM 2.3, the hub cluster collected recommendations from individual clusters from Red Hat Hybrid Cloud. The analytics are generated from the fleet and pushed into the hub cluster itself. RHACM pulls those insights, which are displayed on the Overview page and on the individual cluster Details tab. The reports are categorized into four different levels of severity: low, moderate, important, and critical. When the user investigates the report more, each warning is composed with a solution on how to remediate the issue and the reason behind the warning or rule violation.
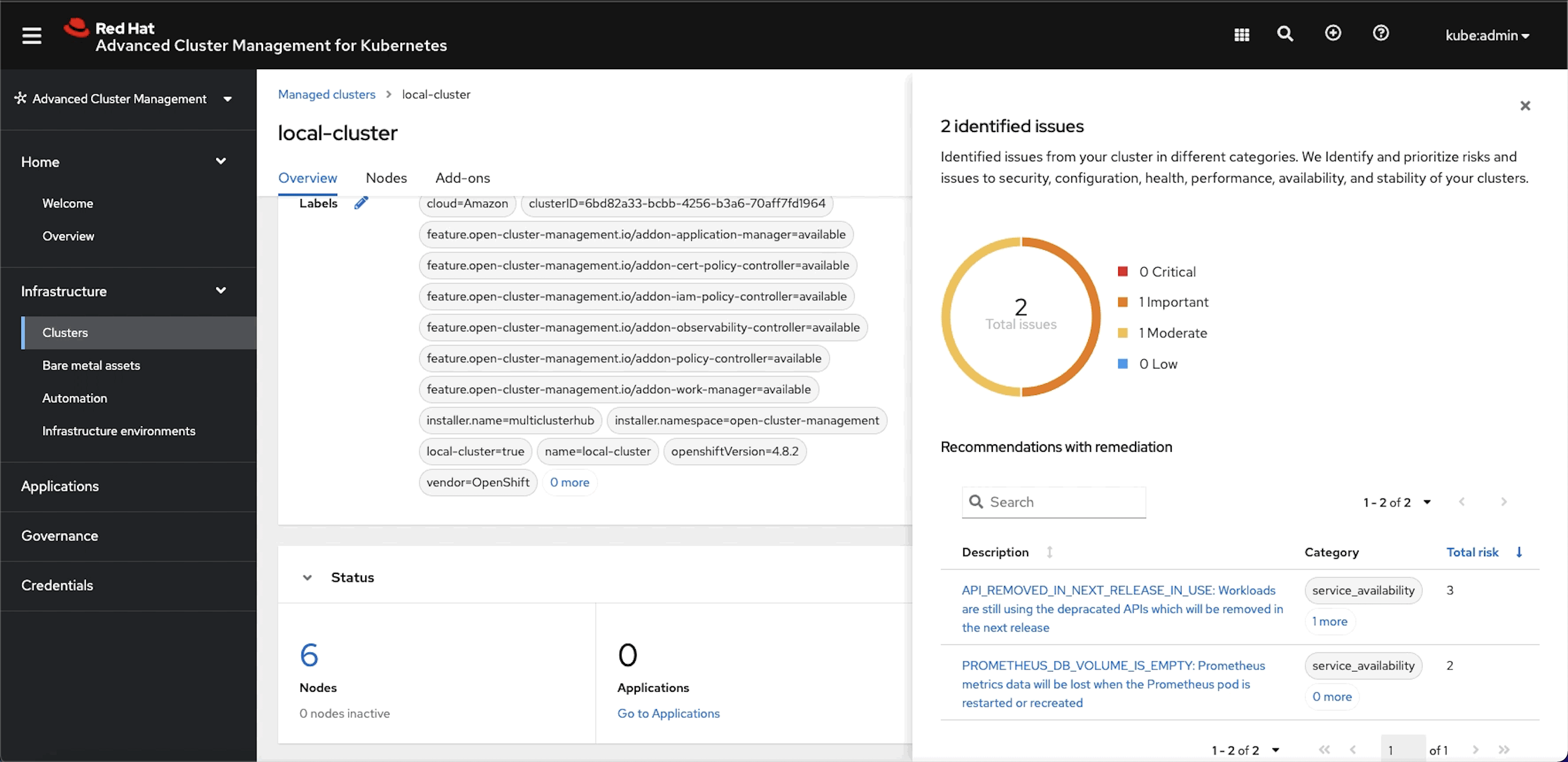 Fig. 2 - Policy report for identified issues in the hub cluster.
Fig. 2 - Policy report for identified issues in the hub cluster.
In the thanos-ruler-default-rules ConfigMap, there is an unique alerting rule to initiate and send the alerts for these warnings and recommendations so the user can view the reports inside, or outside of their cluster environment. See the following YAML sample of a policy report:
- name: policy-reports
rules:
- alert: ViolatedPolicyReport
annotations:
summary: "There is a policy report violation with a {{ $labels.severity }} severity level detected."
description: "The policy: {{ $labels.policy }} has a severity of {{ $labels.severity }} on cluster: {{ $labels.cluster }}"
expr: sum(policyreport_info) by (managed_cluster_id, category, clusterID, policy, severity) > 0
for: 1m
labels:
severity: "{{ $labels.severity }}"
For additional details about the warnings and recommendations provided by the RHACM cluster's policy reports, click on the video down below to view and learn more.
Creating Custom Rules within Observability
In addition to providing out-of-the-box alerting rules and recommended policy reports, observability also support users creating and implementing their own custom Prometheus alerting rules and recording rules. Alerting rules provide the user the ability to specify the alert conditions based on how an alert is configured. Recording rules provide the user the ability to precalculate, or computate expensive expressions as needed.
To begin creating the custom alert conditions, the user must log into their hub cluster. After logging in, the user then creates a ConfigMap named thanos-ruler-custom-rules in the open-cluster-management-observability namespace. Within the ConfigMap, the key is required to be named, custom_rules.yaml.
For instance, you can create a custom alerting rule that notifies you when your cluster service-level objective (SLO) error budget has consumed more than half of its usage. The YAML might resemble the following content:
data:
custom_rules.yaml: |
groups:
- name: cluster-service-level
rules:
- alert: SLOErrorBudgetWarning
annotations:
summary: Notify when SLO error budget utilization on a cluster is greater than the defined utilization limit.
description: "The cluster has consumed more than half of the error budget usage: {{ $value }} for {{ $labels.cluster }} {{ $labels.clusterID }}."
expr: |
0.5 <= (((0.99 - floor(sum_over_time(sli:apiserver_request_duration_seconds:bin:trend:1m{cluster="$cluster"}[$__range])) / count_over_time(sli:apiserver_request_duration_seconds:bin:trend:1m{cluster="$cluster"}[$__range])) / 1)) < 0.8
for: 5s
labels:
cluster: "{{ $labels.cluster }}"
severity: warning
Note that once the thanos-ruler-custom-rules ConfigMap is created, the observability Thanos rule pods refresh automatically before the custom rules are run within the cluster. When the pods are restored, it's important to monitor the status and logs of the pods to make sure that there are no issues occurring in relation to the newly added rules.
To verify that the alerting rules are performing accurately, the user can navigate to the Explore page within Grafana and once again check the ALERTS metrics to identify that their custom alerting rules are either pending or active.
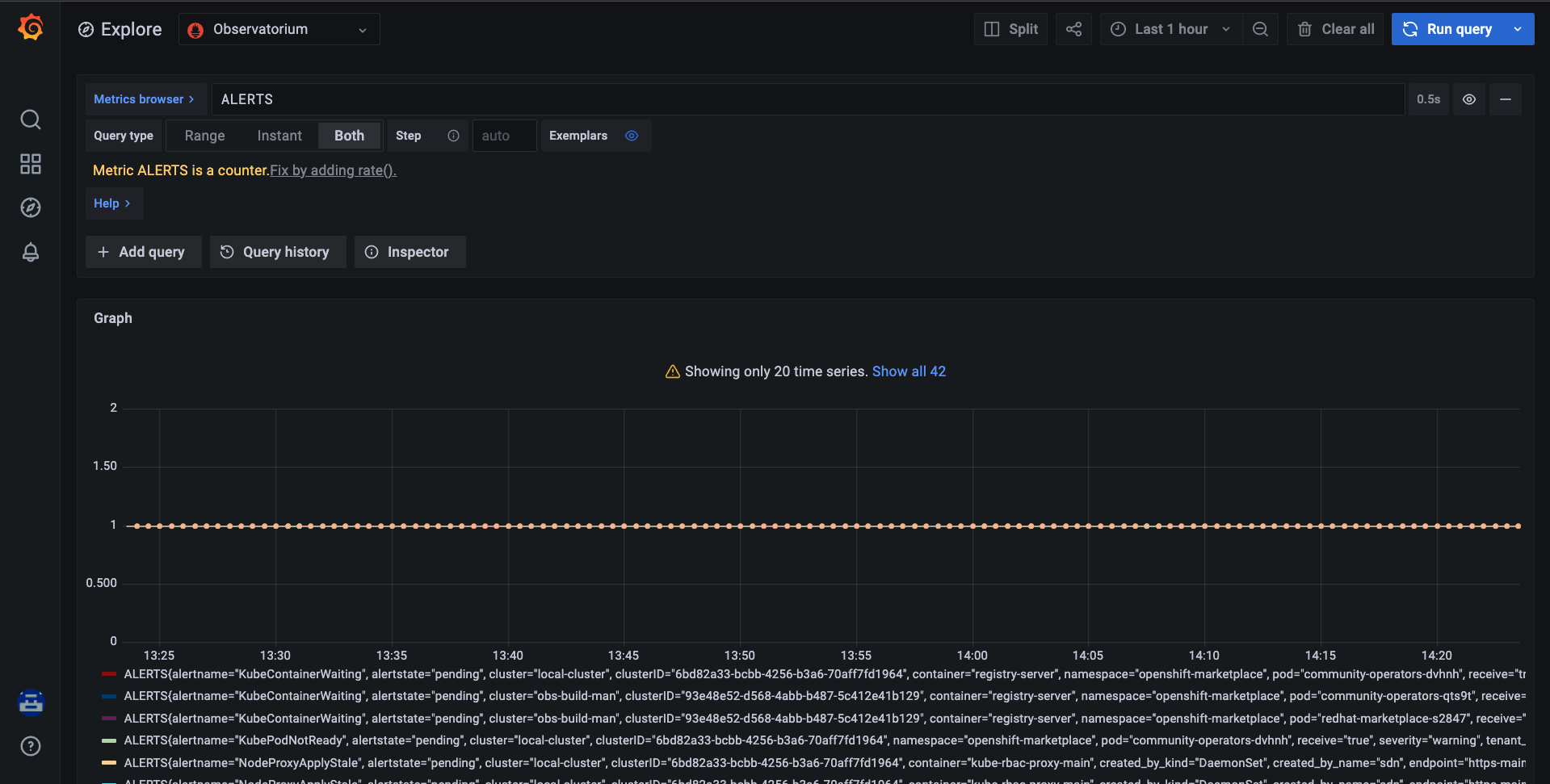 Fig. 3 - Querying for `ALERTS` in Observability Grafana.
Fig. 3 - Querying for `ALERTS` in Observability Grafana.
If the alerts are not displayed, reexamine the rule and identify if the expression is valid. Once the alerts are being properly displayed, the user is one more step closer to initiating their own custom alerts while utilizing their own custom alerting rules.
Configuring the Alertmanager Receiver to Forward Cluster Alerts, Warnings, or Recommendations to Target Application
To begin receiving alerts to Slack, PagerDuty, or the preferred third-party tool, the user is required to modify and update the alertmanager.yaml key within the alertmanager-config secret in the open-cluster-management-observability namespace. By default, the hub cluster alertmanager receiver is set to null as shown in the following example:
"global":
"resolve_timeout": 5m
"receivers":
- "name": null
"route":
"group_by": ["namespace"]
"group_interval": 5m
"group_wait": 30s
"receiver": null
"repeat_interval": 12h
"routes":
- "match":
"alertname": Watchdog
"receiver": null
By updating the secret to route the alerts to the configured receiver, the observability alertmanager then forwards the alerts to the third-party tool that the user selected. The modified alertmanager.yaml key should resemble the following details:
"global":
"resolve_timeout": 5m
"receivers":
- "name": default-receiver
"slack_configs":
- "api_url": https://hooks.slack.com/services/... # Provided by Slack.
"channel": DefaultAlertChannel
"mrkdwn_in": ["text"]
"send_resolved": true
"text": |-
{{ range .Alerts }}
:failed: - *Alerts:* {{ .Annotations.summary }}
:green_book: - *Description:* {{ .Annotations.description }}
:clipboard: - *Details:*
{{ range .Labels.SortedPairs }} • *{{ .Name }}:* {{ if eq .Value `local-cluster` }} `hub` else `{{ .Value }}` {{ end }}
{{ end }}
{{ end }}
"title": "[{{ .Status | toUpper }}] {{ .CommonLabels.alertname }} ({{ .CommonLabels.severity }})"
"route":
"group_by": ["namespace"]
"group_interval": 5m
"group_wait": 30s
"receiver": default-receiver
"repeat_interval": 12h
RHACM also supports configuring more than one route and receiver when forwarding alerts; therefore, if the user wishes to route the alerts to multiple channels or other third-party tools, they can simply achieve this with observability. Also, by default, only the alerts are initiated when their conditions have been met. If the user wishes to be alerted when the issue is resolved, they must set send_resolved: true within the alertmanager-yaml key.
Now that the user has enabled and configured their alertmanager receivers, let's take a deeper look into what the newly created alert might look like. For more details to configure the alertmanager receiver, follow the RHACM 2.4 Observability documentation or visit Prometheus for more information.
Viewing Generated Default and Custom Alerts from Observability
When the alert is generated, it enters a pending state until the alert is initiated and active within observability. In the earlier example, the alertmanager-config secret was updated and set for all of the alerts to be forwarded to the targeted third-party tool, Slack. The alerts are completely customizable; therefore, any users that deploy RHACM observability are able to format and structure their alert to the level of content they desire.
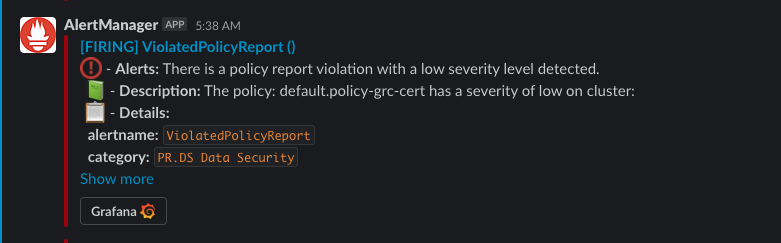 Fig. 4 - Cluster's alert in Slack
Fig. 4 - Cluster's alert in Slack
In the previous figure, the alert is generated based upon the ViolatedPolicyReport alert within the thanos-ruler-default-rules ConfigMap. The customized alert was created to display a summary, description, and a list of details related to the alert for the user to analyze. Alerts can also be designed to perform certain actions, such as linking the user back to their Grafana dashboards from the click of a button.
With the alerts being generated, the user now has more flexibility when monitoring their data. Originally, the user was required to log into their cluster and navigate to Grafana to view their cluster analytics. RHACM observability provides this feature, so users can easily track and preserve a record of these alerts, warnings, and recommendations within a centralized space. Not only is the data more consumable, but the outcome delivered by observability also helps to influence the user with their efforts in maintaining a healthier cluster.
Results
By deploying RHACM observability and configuring the alerting feature, the user is provided a tool that can notify them of the cluster condition with out-of-the-box or customized alerting rules. After the receivers and alerts are set, the user is notified and alerted to the rules that they have arranged within their cluster. It's highly recommended to use this feature with all of the benefits that it provides:
- Removes the heavy dependency on Grafana.
- Grants access to reports and analytics outside of the cluster environment.
- Provides control and freedom for the user to determine what is instrumental for them to observe.
- Contains alerts, warnings, and recommendation reports within a centralized place.
Conclusion
In this post, you were able to observe how an end-user can easily set up and connect into RHACM observability to view the cluster alerts, warnings, and recommendations in a centralized overview. By following this blog, you can see how RHACM observability provides adaptability, along with a tool that increases productivity and awareness into your cluster health.
About the author

More like this
A decade of open innovation: Red Hat continues to scale the open hybrid cloud with Microsoft
Stop managing the past and start building IT’s future
Crack the Cloud_Open | Command Line Heroes
Edge computing covered and diced | Technically Speaking
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds