
As a solutions architect, I spend a lot of my time talking to my customers about Kubernetes. In every one of those conversations, it’s guaranteed that the topic of Kubernetes Operators will come up. Operators, and their relationship to Red Hat OpenShift, aren't always clear to those who are just starting out on their container adoption journey.
Kubernetes has allowed the deployment and management of distributed applications to be heavily automated. A lot of that automation comes out of the box but Kubernetes wasn’t designed to know about all application types. So sometimes it’s necessary to extend the understanding of a specific type of application that Kubernetes has. Otherwise you have to manage a large part of these applications manually that ultimately defeats the purpose of deploying on Kubernetes. Operators allow you to capture how you can write code to automate a task beyond what Kubernetes itself provides.
This post assumes you know what Kubernetes is and how it works and have some knowledge of OpenShift. So what are Operators and why are they so important in explaining what Red Hat OpenShift is?
What are Kubernetes Operators?
Operators are Kubernetes-native applications that add additional knowledge and automation to complex apps. Operators enable software vendors to build their applications to run on top of Kubernetes.
Not only is Red Hat a creator and contributor to some of these projects, but we curate and support a number of them to create a best-in-class container platform.
In OpenShift, these “out of the box” Operators are called cluster Operators. They are installed on Red Hat’s distribution of Kubernetes, Red Hat OpenShift, to provide the functionality and features an enterprise needs from its container platform. From the software-defined network to the console, it’s Operators all the way down.
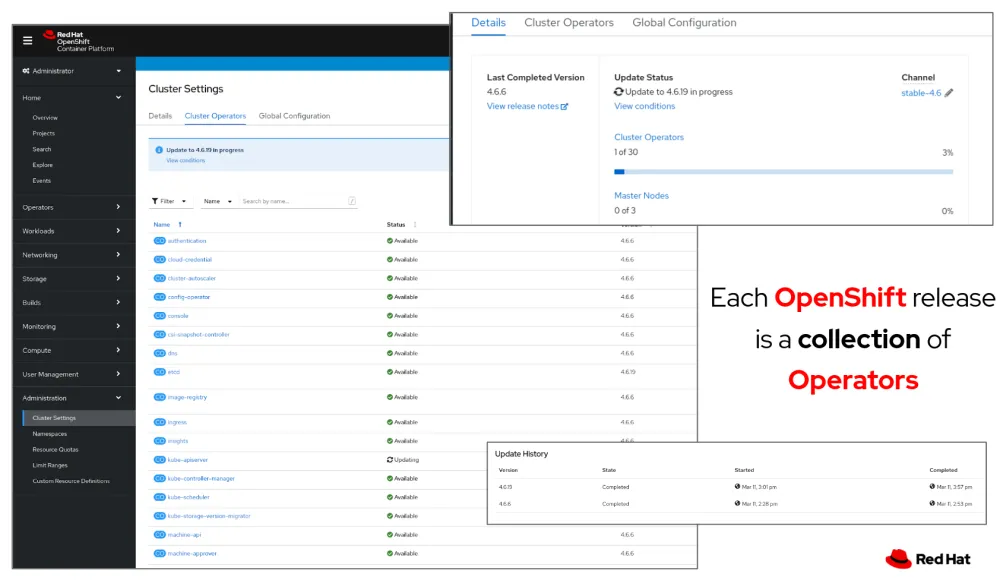
Red Hat OpenShift has 30 Operators out of the box
Cluster operators allow Red Hat to automate installations of Red Hat OpenShift in public or private cloud environments and provide core Day 2 functionality from the outset, including an automated, in-place upgrade process.
OpenShift features 30 Operators, which run each major part of the platform such as version control, ingress, cluster autoscaling and many others. These are fundamental components to have a stable, more secure, and scalable platform to work on. Out of the box, Red Hat includes Operators that make using and operating OpenShift in supported deployment environments the same.
So far, we’ve mainly concentrated on discussing the cluster Operators that Red Hat provides as part of Red Hat OpenShift, allowing you to install and manage a platform going forward. But what about those services that you want to install on your existing clusters to provide operational, development and other services? These can be written in-house or by third-party vendors which require Kubernetes to understand specific domain knowledge about an application (for example, MongoDB, KongEE, Istio, serverless, security or others).
Red Hat’s resources for Operator best practices
In creating and managing a large number of Operators in OpenShift, Red Hat realized there was a need for some best practices for managing app installs and updates on Kubernetes. So the Operator Framework was created, and we use this to certify vendor Operators that Red Hat OpenShift supports.
The framework includes a set of tools to aid in the development of Operators using technologies and language frameworks such as Ansible, Helm, GO or Java and their management, including cluster-admin control on access and installs and upgrade paths. These tools are called the Operator SDK and the Operator Lifecycle Manager (OLM), respectively. The OLM is installed on Red Hat OpenShift out of the box.
To do this on Kubernetes, you need the proper foundations to start. Installing some key Operators on top of any Kubernetes distribution without understanding how they work through updates and different environments is only going to make the adoption in your organization harder. As is going to the effort to build and use an Operator from scratch without a framework to support it.
The OLM fundamentally takes the pain out of writing, developing and managing Operators across multi-tenant Kubernetes clusters. These are tried and tested approaches, and doing it from scratch is really for those people who enjoy doing Kubernetes the hard way.
Kubernetes without Operators? No, thanks.
Without the OLM and the domain knowledge of every layer of the platform, managing Operators and thus the cluster(s) stability becomes really hard to maintain through updates and scale. You do not want to be left debugging Operators on clusters. And without Operators - well, Kubernetes becomes real hard work as you manually do the things an Operator would do to keep service(s) healthy.
So that's why I keep going on about them and if you want to get into this a bit more, I highly recommend reading the Kubernetes Operators ebook.About the author
Mustafa began his career at Red Hat in 2010 as a middleware support engineer and has since held multiple technical roles and responsibilities.
Mustafa currerntly works in the Enterprise EMEA team, supporting some of the largest European Public Sector customers in succeeding in adopting and scaling technologies. As a Principal Solutions Architect, Mustafa has a deep understanding of core business challenges and needs. He applies his technical expertise to support solving real business problems using the best open source solutions. Mustafa is committed to delivering solutions that align with business objectives and works closely with cross-functional teams to ensure successful project delivery on time and within budget. His ability to understand teams and organizations and create high-performing teams and tools to support them has been honed during his tenure at Red Hat.
More like this
Can't patch fast enough? Zero trust as a last line of defense
What's new with image builder for Red Hat Enterprise Linux 10.2 and 9.8
Container Roundup | Compiler
The Containers_Derby | Command Line Heroes
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds