

Enterprise teams often struggle with the "data bottleneck" when building generative AI (gen AI) applications like retrieval-augmented generation (RAG), as traditional document processing tools fail to handle thousands of complex documents efficiently. This blog post explores how a unified infrastructure—combining Ray Data for high-speed streaming and Docling for precise document parsing—removes these hurdles. By scaling these tools on platforms such as Red Hat Openshift AI or Anyscale, organizations can transform messy, unstructured data into actionable insights in hours rather than days, laying the foundation of trust and reliability for the next wave of AI innovation.
Anyscale is the company behind Ray, a framework for distributed computing now part of the PyTorch Foundation. Anyscale also provides an AI platform.
Red Hat OpenShift AI gives organizations a scalable platform to develop and deploy AI. It uses KubeRay to run Ray clusters on Kubernetes, providing improved reliability and automatic scaling. By adding Docling for document parsing, OpenShift AI lets teams manage CPU and GPU tasks on one system. This reduces overhead and speeds up the delivery of AI applications.
The reality of the RAG data bottleneck
Demos make building gen AI look easy, but the reality of data preparation and processing is much more complicated. Imagine your team just inherited tens of thousands of legacy PDFs, and the CEO wants them searchable ASAP. Processing that many complex documents, many with tables and images, can quickly become a bottleneck that takes weeks to clear. The gritty reality is that most AI projects spend the majority of their time wrestling with data preparation rather than training and tuning models.
In many cases, the biggest hurdle in RAG development is the inefficiency of legacy data pipelines. RAG enhances large language model (LLM) responses by retrieving relevant context from a knowledge base. Documents are processed (parsed, chunked, embedded) and stored in a vector database. At query time, relevant chunks are retrieved and provided as context to the LLM, improving response accuracy since they are now grounded in your organization's data, as shown here:
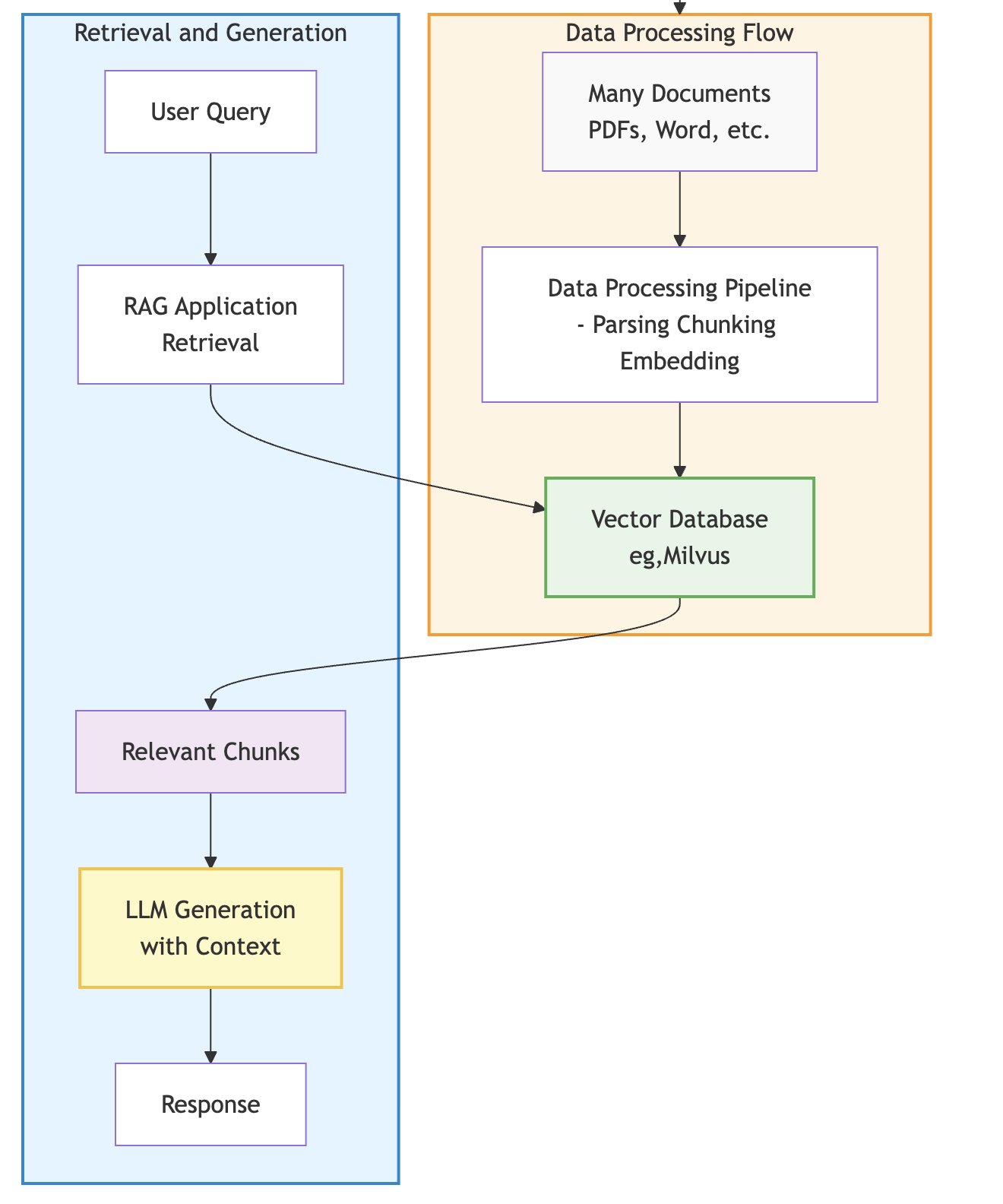
Traditional data processing frameworks often fail to meet the needs of AI because they cannot effectively coordinate the different compute requirements of data processing flow with parsing and embedding documents. To scale AI, enterprise teams must move toward a unified infrastructure that handles both CPU-heavy parsing and GPU-heavy embedding in a single, streamlined process.
Scaling with Ray Data and Docling
Ray Data is a distributed processing library built specifically for AI and machine learning (ML) workloads. Its streaming execution engine pipelines data across CPU and GPU tasks, improving GPU utilization while keeping memory usage constant. Because it is Python-native, it eliminates the serialization overhead of translating data between different language environments, enabling faster iteration cycles for RAG pipelines.
Docling handles the complex parsing that traditional tools often get wrong, helping make sure your AI has the right context to provide useful answers. By accurately parsing tables and layouts in PDFs, Docling helps preserve the semantic structure that makes RAG retrieval more useful. When integrated with Ray Data, each node runs a Docling instance with embedded expert AI models in memory (for processing layouts and tables, for example), allowing for high-performance distributed document processing.
Ray Data streamlines large-scale processing by partitioning datasets into blocks, which are streamed through a cluster to enable massive parallelism. In this architecture, a Ray Data driver manages the execution plan and serializes task code (like Docling processing) for distribution, while the Ray workers handle the actual compute. These workers read data blocks directly from storage and execute parallel writes of the resulting JSON files to the destination, so the driver never becomes a bottleneck, as seen in this architecture:
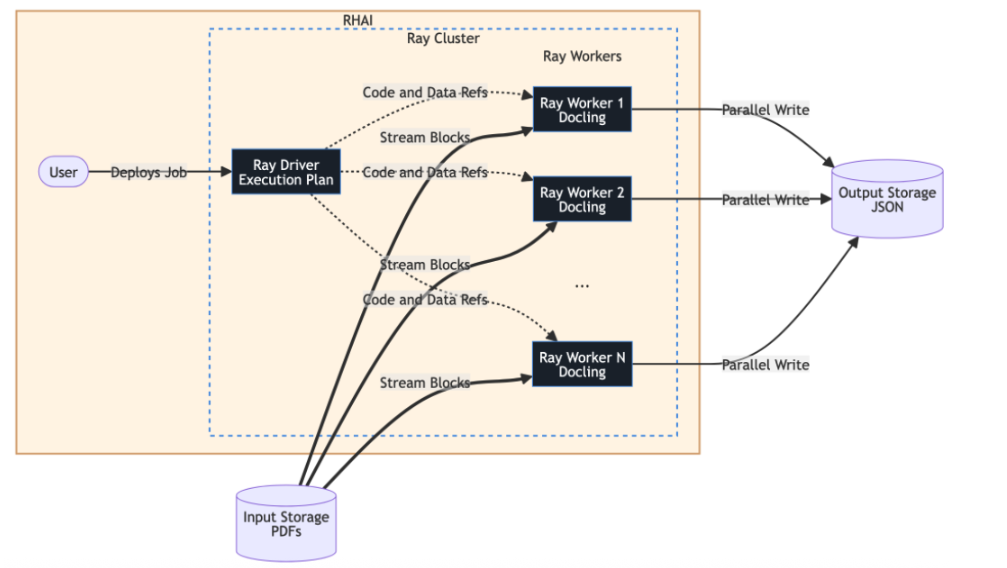
AI data processing architecture
- Ray driver: Manages the ObjectRefs and execution plan, serializing the Docling code for the workers.
- Streaming blocks: The Ray workers pull data directly from input storage in parallel.
- Parallel writing: Each worker writes its processed JSON output directly to storage, so the Ray driver isn't overwhelmed by data throughput.
The integration handles all the distributed complexity, including scheduling, failure recovery, and memory management, automatically. The use of heterogeneous compute allows CPUs to parse while GPUs simultaneously embed data, helping expensive GPU resources be used more efficiently throughout the process.
Enterprise reliability with Red Hat OpenShift AI
OpenShift AI provides the enterprise foundation through KubeRay, orchestrating Ray clusters on Kubernetes with built-in reliability and security features. KubeRay handles operational complexities such as dynamic cluster autoscaling, fault tolerance, and automatic recovery if worker nodes fail. This allows scaling from 10 to 100 nodes transparently to meet the demands of large ingestion jobs.
The end-to-end flow is straightforward, as shown here:
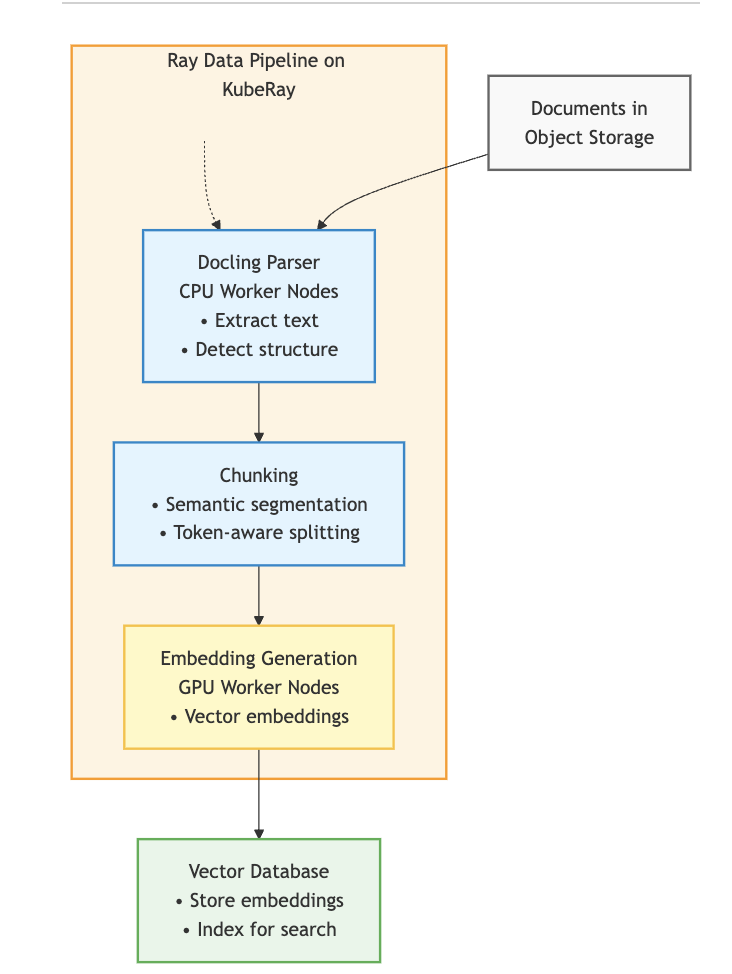
The process goes something like this:
- Documents (for instance, PDFs) land in object storage (such as S3, PVC).
- Ray Data pipeline on OpenShift AI reads these documents and distributes them across worker nodes.
- Docling parses the documents on worker nodes, followed by chunking for the embedding model.
- Embeddings are generated on GPU nodes and written to a vector database like Milvus.
- A RAG application queries the database, feeding context to an LLM to generate accurate responses.
Running on OpenShift AI keeps data processing within the Kubernetes cluster, helping meet data residency requirements and enabling deployment in virtual private clouds or on-premises environments. This unified infrastructure reduces operational overhead by allowing you to run data preparation and model serving on the same platform.
Future outlook: Moving toward agentic solutions
The future of enterprise AI depends on moving past simple search toward sophisticated agentic solutions. Organizations will have to strengthen and further improve their data pipelines to support multistep agentic workflows, where autonomous agents use RAG and retrieval-augmented fine-tuning (RAFT) to solve complex problems. By combining RAG's real-time context with RAFT's ability to "train" a model on how to better ignore irrelevant noise, teams can build agents that are significantly more accurate and reliable.
Those who invest in scalable architectures today will be better positioned to implement these advanced inference chains, where multiple LLM calls happen in sequence with optimal resource allocation. The shift toward agentic AI means that the quality of your processed data is more critical than ever, as agents rely on precise documentation to execute tasks on behalf of users. A robust foundation allows for these creative AI implementations to meet enterprise standards for consistency and safety.
Ultimately, the goal is to make information easy for these AI agents to grasp and act upon. We believe success in gen AI starts with making complex information accessible through an open source foundation with enterprise governance. By establishing a robust, unified platform now, businesses can help their agentic initiatives deliver long-term value and foster trust with their users.
Conclusion
Red Hat OpenShift AI and Anyscale provide the tools needed to turn complex documents into actionable intelligence. By eliminating the data processing bottleneck with Ray Data and Docling, we help organizations focus on what matters most—solving real-world problems.
Register for Red Hat Summit 2026 to connect with our team and explore the future of production AI. You can also try OpenShift AI in the Red Hat Developer Sandbox with 30-day no-cost access to a fully managed environment where you can test these tools.
Product
Red Hat AI
About the authors
Ana Biazetti is a senior architect at Red Hat Openshift AI product organization, focusing on Model Customization, Fine Tuning and Distributed Training.
More like this
Why your AI agent framework isn't enough: 7 platform capabilities missing from production
Demystifying agentic AI: How to build production-ready AIOps with open source models
Technically Speaking | Defining sovereign AI with open source
Technically Speaking | Inside open source AI strategy
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds