
If you’ve worked as a system administrator, you’ve likely been in high stress situations following a system crash that's caused a production outage. In such a situation, the primary objective is to get the production system up and running again as soon as possible. However, as soon as everything is back up and running, your objective must shift to root cause analysis (RCA). You must understand the reason a problem has happened so you can prevent it from happening again.
The Linux kernel is the core of Red Hat Enterprise Linux (RHEL) and handles all the low level details that enable RHEL to operate on a system. When the kernel detects an unrecoverable error, the kernel panics, which results in a system crash. These types of kernel crashes can be caused by various factors, including hardware issues, problems with third-party kernel modules, bugs in the kernel, and so on.
RHEL includes the kdump service. Upon a kernel crash, kdump can boot into a secondary kernel in order to write out a dump of the system memory to a file. This kernel dump file can be analyzed and used to help determine the root cause of the kernel crash. Without a kernel dump file, it's often impossible to determine the root cause.
In production environments, it's important to periodically validate that kdump is properly configured and working (well before you experience a kernel crash).
Options for enabling kdump
There are various methods to enable kdump, including:
- RHEL installer when the system is initially being built
- Manually with the command line
- The kdump helper in the Red Hat Customer Portal Labs
- RHEL web console
- RHEL kdump system role
In this article, I demonstrate how to use the RHEL kdump system role to configure RHEL systems for kernel dumps, and then how to use the RHEL web console to validate that kdump is working properly.
Using the RHEL kdump system role
For an overview of how to get started with RHEL system roles, refer to the Introduction to RHEL system roles blog post.
Note that there were recently a couple of bugs with the kdump system role related to configuring kernel dumps over SSH that have been resolved. The example in this article requires RHEL system roles version 1.22 or later, which is currently available from Ansible Automation Hub (available to customers with an Ansible Automation Platform subscription), and also in the RHEL 8 and RHEL 9 Beta AppStream repositories.
In my environment, I have three RHEL 9 systems. One system acts as my Ansible control node (rhel9-controlnode.example.com), and two are managed nodes that I want to configure kdump on (rhel9-server1.example.com and rhel9-server2.example.com).
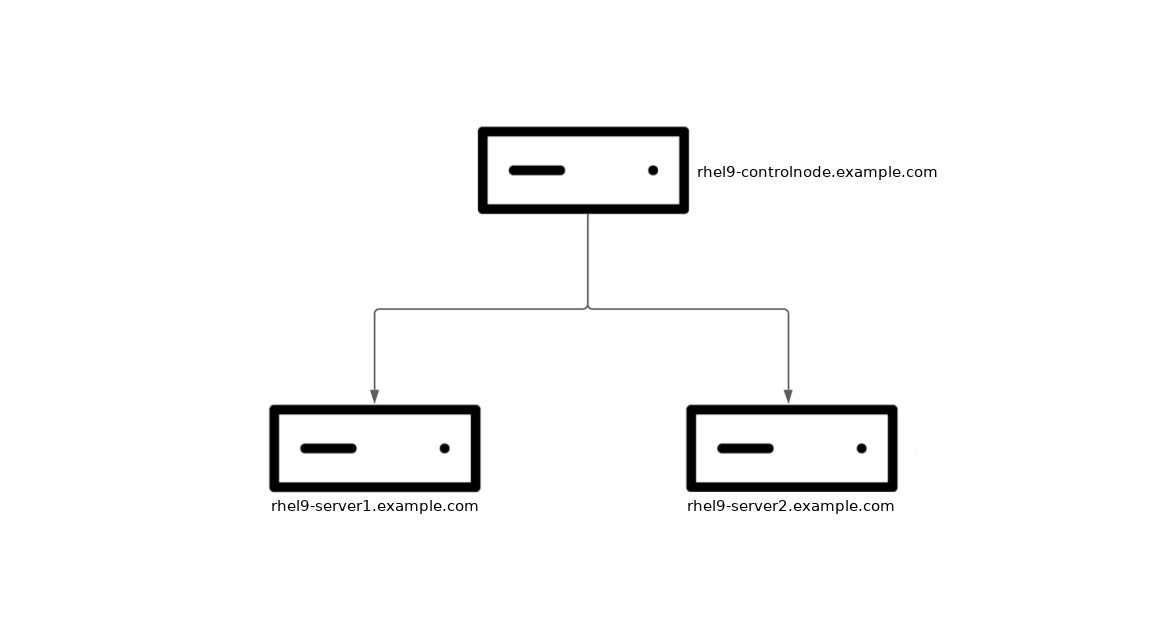
In the event of a crash, the kernel dump can be configured to be written locally on the system, or written out to a remote host over SSH or NFS. In this example, I’d like to configure my two managed nodes to write kernel dumps on the rhel9-controlnode.example.com host over SSH. I’d also like to configure the RHEL web console on each of the managed nodes, so that I can easily verify that kdump is working properly.
From the control node host, start by creating an Ansible inventory file, named inventory.yml, with the following content:
all:
hosts:
rhel9-server1.example.com:
rhel9-server2.example.com:
vars:
kdump_target:
type: ssh
location: kdump@rhel9-controlnode.example.com
kdump_path: "/home/kdump/crash"
kdump_ssh_user: kdump
kdump_ssh_server: rhel9-controlnode.example.com
cockpit_manage_firewall: true
The top of the inventory file lists the two managed nodes. Next, define Ansible variables for the kdump and cockpit RHEL system roles.
- The kdump_target variable specifies that kdumps should be transferred, over SSH, to the rhel9-controlnode.example.com host.
- The kdump_path variable specifies that the kdumps should be written to the /home/kdump/crash directory.
- The kdump_ssh_user and kdump_ssh_server variables specify that the kdumps should be transferred using the kdump user account on the rhel9-controlnode.example.com host (I created this user account on the rhel9-controlnode.example.com host prior to running the kdump system role).
- The cockpit_manage_firewall variable specifies that the cockpit system role should enable the cockpit service in the firewall.
Next, define the Ansible playbook, named system_roles.yml, with the following content:
- name: Run RHEL kdump system role
hosts: all
roles:
- redhat.rhel_system_roles.kdump
- name: Run RHEL cockpit system role
hosts: all
roles:
- redhat.rhel_system_roles.cockpit
This playbook calls the RHEL kdump and cockpit system roles.
Run the playbook with the ansible-playbook command:
$ ansible-playbook -i inventory.yml -b system_roles.yml
In this example, I specify that the system_roles.yml playbook should be run, that it should escalate to root (the -b flag), and that the inventory.yml file should be used as my Ansible inventory (the -i flag).
In my environment, the role fails on the Fail if reboot is required and kdump_reboot_ok is false task.

Configuring kdump may require the system to be rebooted. If I had set the kdump_reboot_ok variable to true in the inventory file, the hosts would have automatically rebooted. In this example, I manually reboot the hosts, and then run the playbook again. The second run of the playbook completes successfully.

Check the kdump configuration
On each of the two managed nodes, the kdump system role created a new SSH key, stored under /root/.ssh/kdump_id_rsa, and configured the kdump.conf configuration file.
On the control node host, rhel9-controlnode.example.com, the kdump system role configured the kdump user accounts authorized_keys file with the corresponding public keys from each of the two managed nodes.
The best method to validate that everything is working properly is to crash the kernel on each of the managed nodes, and validate that the kernel dumps are properly created. Warning: crashing a kernel causes downtime on the system! Do this only during a maintenance window.
You can force a kernel crash from the command line, or using the web console.
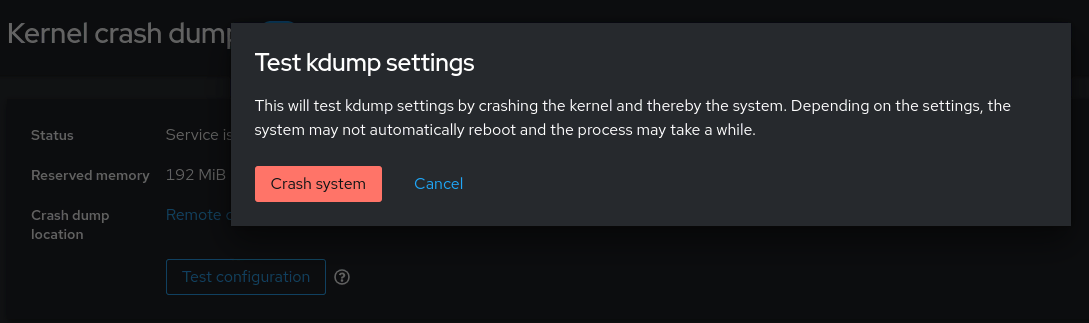
Log in to each of the managed nodes using the RHEL web console by connecting to their host names on port 9090 using a web browser. After you've logged in, select Kernel dump in the menu on the left, and then click the Test configuration button. A warning message is brought up that this will crash the kernel.
Now check the /home/kdump/crash directory on the rhel9-controlnode.example.com host.
[rhel9-controlnode]$ ls -l /home/kdump/crash/ total 0 drwxr-xr-x. 2 kdump kdump 72 Sep 6 15:07 192.168.122.102-2023-09-06-15:07:39 drwxr-xr-x. 2 kdump kdump 72 Sep 6 15:07 192.168.122.103-2023-09-06-15:07:44
A directory was created for each host when the kernel dump occurred, with the directory names indicating the IP address and date/time that the crash occurred. Kernel dump files were created, too:
[rhel9-controlnode]$ ls -l /home/kdump/crash/192.168.122.103-2023-09-06-15\:07\:44/ total 99120 -rw-------. 1 kdump kdump 77622 Sep 6 15:07 kexec-dmesg.log -rw-------. 1 kdump kdump 66633 Sep 6 15:07 vmcore-dmesg.txt -rw-------. 1 kdump kdump 101350015 Sep 6 15:07 vmcore.flat
It's recommended that the kdump functionality be routinely tested to validate that it's working properly. This is especially important when there are changes on the system, such as patching, storage changes, hardware replacements, and changes at the network layer (if the kdump target is set to SSH or NFS), and so on.
Conclusion
If one of your RHEL systems ever has a kernel crash, would you have a need to determine the cause? If so, it is critical that you properly configure and test kernel dumps in your RHEL environment. The RHEL kdump system role enables you to configure kernel dumps across your RHEL environment at scale using automation. Feel free to reach out by opening a support ticket with our Global Support Services (GSS) team if you face any challenges in setting up kdump in your RHEL environment.
About the author
Brian Smith is a product manager at Red Hat focused on RHEL automation and management. He has been at Red Hat since 2018, previously working with public sector customers as a technical account manager (TAM).
More like this
Red Hat Lightspeed on premise delivers infrastructure intelligence inside your firewall
Friday Five — June 19, 2026
Infrastructure At The Edge | Compiler
Operating System Management | Compiler
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds