
システム管理者として働いたことがある方なら、おそらくプロダクション環境の停止を伴うシステムクラッシュが発生して極度のストレスがかかる状況に置かれたことがあるでしょう。このような状況での最大の目標は、できるだけ早くプロダクションシステムを稼働状態に戻すことです。しかし、すべてが元の状態に戻ったらすぐに、目的を根本原因分析 (RCA) に移す必要があります。問題の再発を防止するには、問題が発生した理由を理解しなければなりません。
Linux カーネルは Red Hat Enterprise Linux (RHEL) のコアであり、RHEL がシステム上で動作するために必要な下位レベルの詳細をすべて処理します。カーネルが回復不可能なエラーを検出すると、カーネルパニックが発生し、システムがクラッシュします。このようなカーネルクラッシュは、ハードウェアの問題、サードパーティーのカーネルモジュールの問題、カーネルのバグなど、さまざまな要因によって発生します。
RHEL には、kdump サービスが含まれています。カーネルがクラッシュすると、kdump は別のカーネルを起動してシステムメモリーのダンプをファイルに書き込むことができます。このカーネルダンプファイルを分析して、カーネルクラッシュの根本原因を特定するために使用できます。カーネルダンプファイルがないと、多くの場合、根本原因を特定することはできません。
プロダクション環境では、 kdump が適切に設定され、機能していることを定期的に (カーネルのクラッシュが発生する前に余裕をもって) 検証することが重要です。
kdump を有効にするためのオプション
kdump を有効にするには、次のような複数の方法があります。
- システムを最初にビルドする際に RHEL インストーラーを使用
- コマンドラインを使用して手動で実行
- Red Hat カスタマーポータルラボの kdump helper
- RHEL Web コンソール
- RHEL kdump システムロール
この記事では、RHEL kdump システムロールを使用して RHEL システムのカーネルダンプを設定する方法と、RHEL Web コンソールを使用して kdump が正常に動作していることを確認する方法を説明します。
RHEL kdump システムロールの使用
RHEL システムロールを使用方法の概要については、ブログ記事「RHEL システムロールの概要」を参照してください。
最近、SSH を介したカーネルダンプの設定に関連して kdump システムロールにいくつかのバグがありましたが、それらのバグは解決されています。この記事の例では RHEL システムロールのバージョン 1.22 以降が必要です。これは現在、Ansible Automation Hub (Ansible Automation Platform サブスクリプションをお持ちのお客様がご利用いただけます) から入手でき、RHEL 8 および RHEL 9 ベータ版の AppStream リポジトリにもあります。
私の環境には、3 つの RHEL 9 システムがあります。1 つのシステムは Ansible コントロールノード (rhel9-controlnode.example.com) として機能し、あとの 2 つはマネージドノード (rhel9-server1.example.com と rhel9 -server2.example.com) で、これらに kdump を設定します。
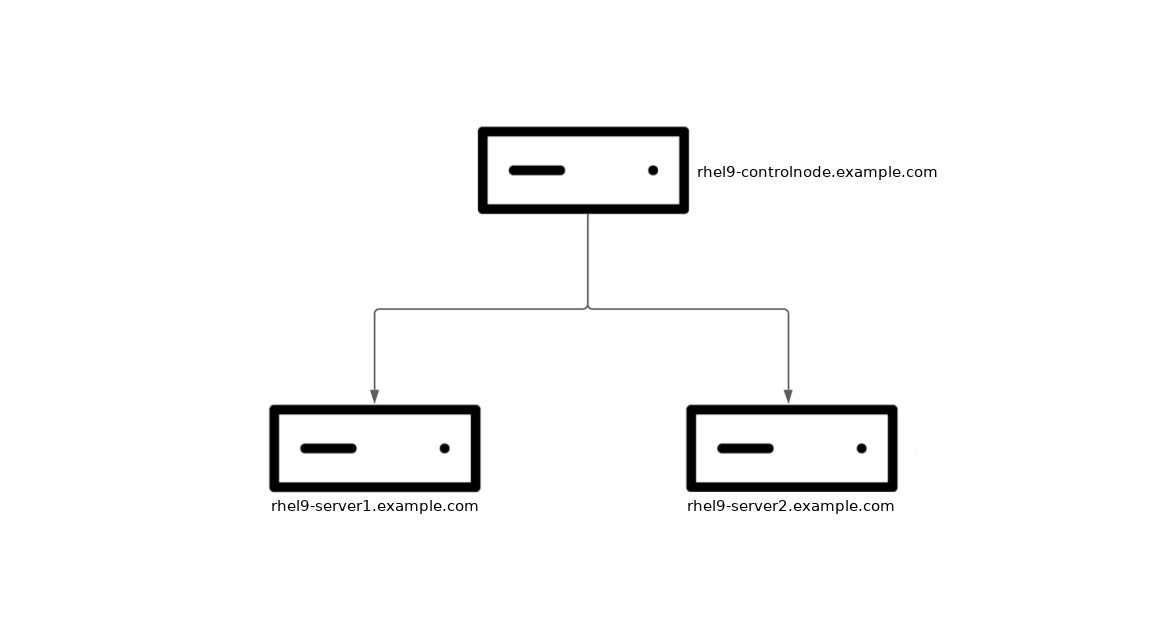
クラッシュが発生した際にカーネルダンプを書き込む場所は、ローカルのシステムにするか、SSH または NFS を介してリモートホストにするかを設定できます。この例では、SSH を介して rhel9-controlnode.example.com ホストにカーネルダンプを書き込むように 2 つのマネージドノードを設定します。また、各マネージドノードで RHEL Web コンソールを設定して、kdump が正常に動作していることを簡単に確認できるようにします。
コントロールノードホストから、まず inventory.yml という名前の Ansible インベントリーファイルを作成します。ファイルの内容は以下のようにします。
all:
hosts:
rhel9-server1.example.com:
rhel9-server2.example.com:
vars:
kdump_target:
type: ssh
location: kdump@rhel9-controlnode.example.com
kdump_path: "/home/kdump/crash"
kdump_ssh_user: kdump
kdump_ssh_server: rhel9-controlnode.example.com
cockpit_manage_firewall: true
インベントリーファイルの先頭に、2 つのマネージドノードがリストされています。次に、RHEL の kdump システムロールおよび cockpit システムロール用に Ansible 変数を定義します。
- kdump_target 変数は、SSH を介して kdumps を rhel9-controlnode.example.com ホストに転送するよう指定します。
- kdump_path 変数は、kdump を /home/kdump/crash ディレクトリに書き込むように指定します。
- kdump_ssh_user 変数および kdump_ssh_server 変数は、rhel9-controlnode.example.com ホスト上の kdump ユーザーアカウントを使用して kdump を転送するよう指定します (このユーザーアカウントは、kdump システムロールを実行する前に rhel9-controlnode.example.com ホストで作成しているユーザーアカウントです)。
- cockpit_manage_firewall 変数は、cockpit システムロールがファイアウォールで cockpit サービスを有効にするよう指定します。
次に、system_roles.yml という名前の Ansible Playbook を定義します。内容は以下のようにします。
- name: Run RHEL kdump system role
hosts: all
roles:
- redhat.rhel_system_roles.kdump
- name: Run RHEL cockpit system role
hosts: all
roles:
- redhat.rhel_system_roles.cockpit
この Playbook は、RHEL の kdump システムロールと cockpit システムロールを呼び出します。
ansible-playbook コマンドを使用して Playbook を実行します。
$ ansible-playbook -i inventory.yml -b system_roles.yml
この例では、system_roles.yml Playbook を実行すること、root にエスカレーションすること (-b フラグ)、および inventory.yml ファイルを Ansible インベントリとして使用すること ( -i フラグ) を指定しています。
私の環境では、ロールは Fail if reboot is required and kdump_reboot_ok is false タスクで失敗します。

kdump を設定するには、システムの再起動が必要になる場合があります。インベントリーファイルで kdump_reboot_ok 変数を true に設定していた場合は、ホストは自動的に再起動します。この例では、ホストを手動で再起動してから、この Playbook を再度実行します。Playbook の 2 回目の実行は正常に完了します。

kdump の設定の確認
2 つのマネージドノードのそれぞれで、 kdump システムロールによって新しい SSH キーが作成されて /root/.ssh/kdump_id_rsa に保存され、kdump.conf 設定ファイルが設定されました。
コントロールノードホスト rhel9-controlnode.example.com で、 kdump システムロールによって、2 つのマネージドノードそれぞれの対応する公開鍵を使用して kdump ユーザーアカウント authorized_keys ファイルが設定されました。
すべてが正常に動作していることを確認する最善の方法は、各マネージドノードのカーネルをクラッシュさせ、カーネルダンプが適切に作成されることを確認することです。注意:カーネルをクラッシュさせると、システムでダウンタイムが発生します。そのため、必ずメンテナンス期間中にのみ実行してください。
コマンドラインまたは Web コンソールを使用して、カーネルを強制的にクラッシュさせることができます。
Web ブラウザーを使用してポート 9090 でホスト名に接続し、RHEL Web コンソールで各マネージドノードにログインします。ログインしたら、左側のメニューで Kernel dump を選択し、Test configuration ボタンをクリックします。カーネルがクラッシュすることを示す警告メッセージが表示されます。
rhel9-controlnode.example.com ホスト上の /home/kdump/crash ディレクトリをチェックします。
[rhel9-controlnode]$ ls -l /home/kdump/crash/ total 0 drwxr-xr-x. 2 kdump kdump 72 Sep 6 15:07 192.168.122.102-2023-09-06-15:07:39 drwxr-xr-x. 2 kdump kdump 72 Sep 6 15:07 192.168.122.103-2023-09-06-15:07:44
カーネルダンプが発生したときに各ホストのディレクトリが作成されており、ディレクトリ名は IP アドレスとクラッシュが発生した日付および時刻になっています。カーネルダンプファイルも作成されています。
[rhel9-controlnode]$ ls -l /home/kdump/crash/192.168.122.103-2023-09-06-15\:07\:44/ total 99120 -rw-------. 1 kdump kdump 77622 Sep 6 15:07 kexec-dmesg.log -rw-------. 1 kdump kdump 66633 Sep 6 15:07 vmcore-dmesg.txt -rw-------. 1 kdump kdump 101350015 Sep 6 15:07 vmcore.flat
kdump 機能は、定期的にテストして、正しく動作するかどうかを検証することをお勧めします。これは、パッチ適用、ストレージの変更、ハードウェアの交換、ネットワークレイヤーでの変更 (kdump ターゲットが SSH または NFS に設定されている場合) など、システムに変更が加えられた場合にとくに重要です。
まとめ
RHEL システムのいずれかでカーネルがクラッシュした場合、原因を特定する必要がありますか?もしそうなら、RHEL 環境でカーネルダンプを適切に設定してテストすることが不可欠です。RHEL の kdump システムロールを使うと、自動化により RHEL 環境全体でカーネルダンプを大規模に設定することができます。RHEL 環境での kdump の設定に関連した問題が発生した場合は、サポートチケットを作成して、グローバルサポートサービス (GSS) チームまでお気軽にお問い合わせください。
執筆者紹介
Brian Smith is a product manager at Red Hat focused on RHEL automation and management. He has been at Red Hat since 2018, previously working with public sector customers as a technical account manager (TAM).
類似検索
vi エディター入門
急激に進化する AI の脅威に対応する防御作とは
Container Roundup | Compiler
Untangling Networks | Compiler
チャンネル別に見る

自動化
テクノロジー、チームおよび環境に関する IT 自動化の最新情報

AI (人工知能)
お客様が AI ワークロードをどこでも自由に実行することを可能にするプラットフォームについてのアップデート

オープン・ハイブリッドクラウド
ハイブリッドクラウドで柔軟に未来を築く方法をご確認ください。

セキュリティ
環境やテクノロジー全体に及ぶリスクを軽減する方法に関する最新情報

エッジコンピューティング
エッジでの運用を単純化するプラットフォームのアップデート

インフラストラクチャ
世界有数のエンタープライズ向け Linux プラットフォームの最新情報

アプリケーション
アプリケーションの最も困難な課題に対する Red Hat ソリューションの詳細
仮想化
オンプレミスまたは複数クラウドでのワークロードに対応するエンタープライズ仮想化の将来についてご覧ください