
This post is part 3 of my post-quantum series. Part 1 introduced quantum computers and why we need new crypto standards. Part 2 introduced hash-based signatures, how they work, and what their issues are. In this article I introduce the leading popular replacement for classical algorithms: lattice-based cryptography. The goal of this blog post is to give you a basic intuitive understanding of how lattice cryptography works, and how it can be safely used. I won’t get into the deep mathematics or proofs surrounding lattices (other than to point out the limits of those proofs).
What is lattice-based cryptography?
Lattice-based cryptographic systems are a whole class of systems based on hard questions around spaces formed by combining sets of vectors to form new vectors. All the new vectors you can form by these combinations are called a lattice.
A lattices is usually introduced as 2D or 3D vectors (vectors with 2 or 3 variables), because you can draw pictures that can make some intuitive sense. In practice, the number of variables of the vectors can be arbitrary and for cryptography they are much greater than 3.
Below is an example of a lattice formed by two two-dimensional vectors (one represented in solid red lines, the other in a black dashed line).
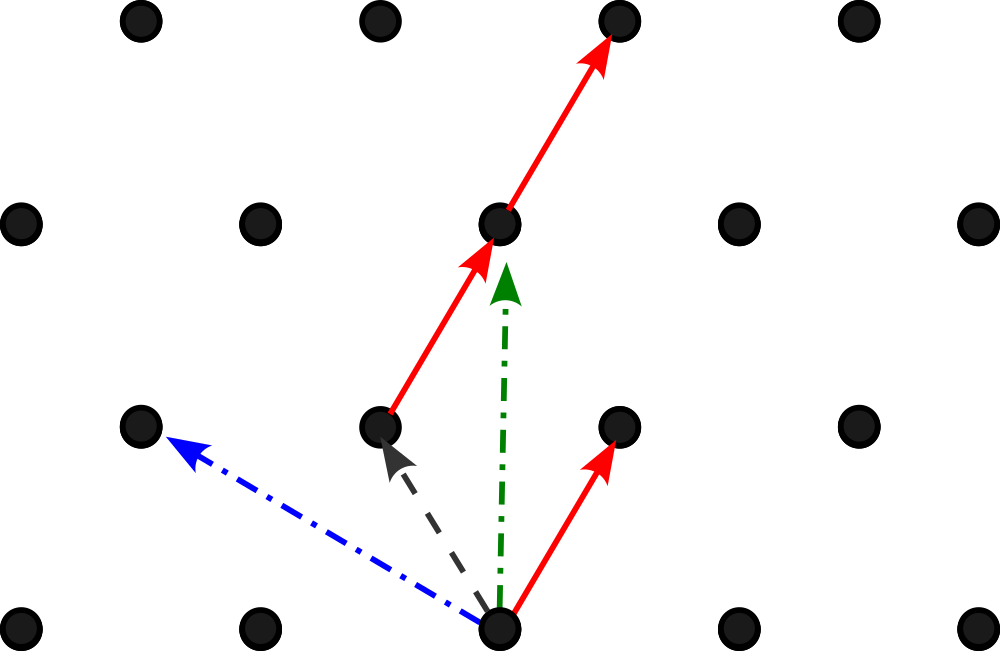
Some interesting characteristics of lattices is that you can form the same lattice with different vectors. For instance, the blue and green vectors (the dot-dashed lines) can be used to form the same lattice. We call the set of vectors which define a lattice as the ‘basis’ of the lattice.
Hard problems
There are a couple of long-standing hard problems when dealing with lattices. Essentially, if you can solve one of them, then that provides a solution to others as well.
- Shortest vector problem: In general, it’s difficult to determine the shortest vector in a lattice.
- Closest vector problem: Given a vector, find the vector that is closest to the given vector. Intuitively, you can see if you can solve this, you can solve the shortest vector problem simply by finding the vector closest to the origin. Conversely, if you can solve the shortest vector problem, you can do coordinate transform and find the closest vector to an arbitrary vector.
- SVIP problem: Find the basis for a lattice with the shortest possible vectors. If you solve this, you can find the shortest vector by finding the shortest vector in your basis. If you have a way to find the shortest vector, you can use that recursively to find the set of shortest possible vectors in a basis.
These three problems have been rigorously proved to be equivalent (solving any one of them solves the others). While there have been proposed cryptographic systems that use these problems directly, most proposals use other problems and try to show that these other problems are equivalent to one of these three problems.
Practical considerations
Operating on sets of vectors isn’t very convenient, so the lattice basis is usually represented as an array. The vectors themselves form the columns and each value in the vector forms a row. This allows you to use regular matrix operations to do calculations in the lattice.
The other consideration is how you represent the vectors. As with classical cryptography, you can map these vectors into finite fields (either prime fields or binary fields). The main difference between the fields used in lattice operations and those used in Diffie-Helman or Elliptic Curves is one of size. Lattice fields usually fit within the computer’s word size, so there is no need to use special big integer arithmetic libraries. The security doesn’t come from the size of our vector values, but in the size of the vectors and the number of vectors in our basis.
Learning with errors
One of the most fruitful lattice problems comes from the field of AI. Say you have a set of data you want to use to train your AI. The data consists of a set of variables and a resulting output. The problem is this data may have been created by measuring real world output, which may have some noise in it. You would like to remove the noise and reclaim the original data. (A second, related problem is to identify that a given data set has noise in it). Unfortunately for AI developers, it turns out this problem reduces to our lattice shortest vector problem. Fortunately for us, the problem can be turned into a cryptographic system. In a Learning with Errors (LWE) system we take some square array A. We can take a secret vector s and calculate a value vector b with following formula (in all the text below multi-valued variables like arrays, vectors, and later functions are depicted in bold).
b = s ∙ A + e
where b, s, and e are vectors and A is an array. The value e is a small error vector.
In general, s can’t be recovered from just A and b. You can now use this as you would a normal Diffie-Hellman like key exchange:
Alice generates sa and e1 as small magnitude random vectors. A is either generated or comes from a trusted source. Alice then calculates ba as:
ba = sa ∙ A + e1
Alice’s public key is the vector ba and her private key is the vector sa. A is a common array used by both Bob and Alice. Alice sends ba and A to Bob. Alice throws away vector e1.
Bob generates sb and e2 as small magnitude random vectors. He calculates bb as:
bb = A ∙ sb + e2
Bob then calculates key as:
kb = ba ∙ sb = sa ∙ A ∙ sb + e1 ∙ sb
Finally Bob sends bb to Alice who calculates:
ka = sa ∙ bb = sa ∙ A ∙ sb + sa ∙ e2
Note that kb and ka are only different from each other by e1 ∙ sb and sa ∙ e2. Since errors and s values are chosen with small values, we can use error correction or truncation to remove the differences.
This varies from a traditional Diffie-Helman in these ways:
- We have a small percentage chance of getting the wrong answer, even if Bob and Alice runs the protocol correctly
- Because matrix/vector operations aren’t commutative, Bob and Alice have to do their operations in different orders (so extending this protocol to additional parties requires care)
- If we try to do more operations, the error values grow and the chance of a failure increases
Reducing the size with rings
Safe versions of this protocol require large matrices, which generates large keys. One way to reduce this is to replace all our matrix operations with operations on polynomial functions. Our equations look the same, but the underlying math is different. Instead of array operations, we turn the array and vectors into a polynomial. So if we have a vector: <a1, a2, a3> we can map it to the polynomial a1x2+a2x+a3. So b, s, e, and A all become polynomial functions.
b = s*A + e
This equation can be used in the same protocol as we did with the standard LWE where s is still the private key and b is the public key, but now they are polynomials instead of vectors and matrices.
The multiplication is a standard polynomial multiply that is reduced modulo a polynomial (usually xn+1). This forms what's called a ring, so this is called Ring Learning with Errors (RLWE).
Below is an example of a polynomial multiplication over a ring (and like array operations, all the math is done in a finite field, in this case mod prime q:
a * b, a=<3 3 3> b=<2 1 1> q=5, m=x3+1
3x2+ 3x + 3
2x2 + x + 1
x4+ 4x3+2x2+ x + 3 (polynomial multiply of a and b, coefficients mod 5)
-x4 + -x (subtract x(x3+1))
4x3+ 2x2+0x + 3
-4x3 + -4 (subtract 4(x3+1))
2x2+0x + 4 => <2 0 4>
When we use the RLWE, our formal proofs of difficulty no longer hold. We can’t show that solving the RLWE allows us to solve any of our basic Lattice problems.
NTRU (N-th degree Truncated polynomial Ring Units)
Once we see how RLWE works, we can use polynomial functions in another way. In NTRU, we generate two random polynomial functions, g and f. We then find two other functions, fp and fq such that f * fp = 1 mod p and f * fq = 1 mod q where p and q are part of our NTRU parameter set (q >> p). The functions fp and fq can be calculated using Euclid’s algorithm (the same algorithm used to find the multiplicative inverse in a finite field). Once we have all of these functions, we calculate h as
h=pfq*g (mode q)
The public key is h, and f and fp are saved as the private key.
To encrypt, choose a random polynomial function r and map your message into a polynomial function m. Calculate
c=r*h + m (mod q)
with c as the ciphertext.
To recover m, the owner of the private key fist multiplies c with f.
v=c*f (mod q)
This results in v=pr*f*fq*g + f*m (mod q) = pr*g + f*m (mod q).
Now recover m
m’=fp*v (mod p) = pr*fp*g + f*fp*m (mod p) = 0 + m (mod p) = m.
Crystals-Kyber
One of the accepted algorithms of the NIST Post Quantum Algorithm Project is Kyber. Kyber is a Module Learning with Errors (MLWE), where A is a 2 by 2 array of polynomial functions, rather than a single polynomial function, and b, s and e are vectors of 2 polynomial functions. All the math and equations are the same as in Learning with errors above, except instead of multiplying numbers, we're doing polynomial multiplication. Kyber uses truncation to both introduce additional errors, as well as to remove errors in the decryption case.
Kyber creates a key encryption algorithm (KEA) based on the Diffie-Hellman like LWE described above. Alice generates her public key (ba) as normal. Bob encrypts to Alice by calculating kb and adding it to the message m (which has been shifted left to keep the message clear of any errors). Bob sends his public key (bb) and c=kb+m to Alice. Alice decrypts by using bb and private key sa to calculate ka and subtracting ka from c to get m (which Alice shifts right to remove any errors).
Kyber turns this KEA into a key encapsulation mechanism (KEM). To encapsulate, make the message (m) a random value, calculate a check value for m and the public key, encrypt m and the check value using the Kyber KEA, and create a key from a kdf with m, the public key and the cipher text. On decapsulate, m and the check value are decrypted using the Kyber KEA from the cipher text and private key, a new cipher text is calculated and verified against the actual cipher text, if they fail, m is replaced by a fixed random key stored as part of the private key. Then m, public key and cipher text are used in a kdf to generate a key.
Lattice operations can be vulnerable to error injection attacks, so the KEM form is important to prevent these attacks. It’s also important to make sure the error processing does not leak side channel data.
Kyber comes in 3 flavors, with the following key sizes:
| Public Key Size (bytes) | Private Key Size (bytes) | Cipher Text Size (bytes) | |
| Kyber512 | 800 | 1632 | 768 |
| Kyber768 | 1184 | 2400 | 1088 |
| Kyber1024 | 1568 | 3168 | 1568 |
By comparison, RSA 2048 has a public key size of 260 bytes, private key size of 900 bytes and a cipher text size of 256 bytes.
Crystals-Dilithium
Dilithium is a signature algorithm based on MLWE. Public and private keys are generated just like Kyber (though the parameters are different). However, the way they are used is completely different.
To sign, signer generates random vector y with coefficients under a given threshold. He calculates:
w=HighBits(A∙y)
c=HASH(m || w)
z=y+c∙s
In this equation, s is the MLWE private key, A is the MLWE array, and m is the message to sign. The signer then verifies that all the coefficients of z are below a threshold, and that Lowbits of (A∙y-c∙e) are also below a (different) threshold (where e is the error vector used in generating the MLWE public key). If these conditions don’t hold, a new y is generated and the signer goes through the process again. Once a suitable z is generated, z and c are returned as the signature.
To verify, the verifier calculates
w’=HighBits(A∙z-c∙b)
In this equation, b is the MLWE public key. If c=HASH(m || w’), and the coefficients of z are under the threshold, then the signature is valid.
Here’s why it works. The signer knows the secret value s, which allows him to generate likely z candidates with small enough coefficients to be valid. To see that w=w’ (which is necessary for c to match the hash of m and w’), remember
b=A∙s+e
z=y+c∙s
therefore
A∙z-c∙b=A∙y+c∙A∙s-cA∙s-c∙e=A∙y-c∙e
Because the signer verified that A∙y-c∙e wouldn’t generate a borrow from the high bits, we know that HighBits(A∙y)=HighBits(A∙y-c∙e)=HighBits(A∙z-c∙b), so w=w’.
Dilithium comes in three flavors.
| Public key size (bytes) | Signature size (bytes) | |
| Dilithium 2 | 1312 | 2420 |
| Dilithium 3 | 1952 | 3293 |
| Dilithium 5 | 2592 | 4595 |
Issues to worry about
All lattice based cryptography is relatively new, and module based systems are even newer. We are still trying to analyze the systems, and attacks that shave off some of the security continue to be found. Our initial uses of these cryptographic systems will likely be combined with our classical systems called hybrid systems. A Kyber key and an ECC key are used to generate a single session key which uses both the Kyber portions and the ECC portions. If one of these systems is compromised, the key is still secure.
A second thing to worry about is making sure your implementation is not leaking side channel data. This usually happens when key exchange failures happen. Just like hiding PKCS #1 v1.5 failures in RSA decryption, Kyber must hide decapsulation failures.
Lattices depend on generating secure random A matrices. If the attacker can get you to use a cooked A matrix, then he can give you a matrix that he can find the private key s through a special function that knows how to reverse cooked A. Kyber specifies A generated with a prf which guarantees A will be random.
Implementing lattice cryptography securely will be tricky, so it’s best to rely on well tested and verified implementations, as well as following all the NIST recommendations for how to use these functions. Be very careful of trying to roll your own modifications to the standards. Use protocols that have hybrid key exchanges in them to insulate against possible compromise.
Conclusions
Lattice provides the closest drop in replacements for our existing algorithms with only modest key size increases and still have some confidence in their security. That is why 3 of the 4 NIST finalists are lattice based cryptographic systems. They can be tricky to implement, so be sure to use tested and verified implementations as well as make sure you use these systems as specified without your own protocol tweaks. Finally, whenever possible use them in hybrid systems while we still conduct further research.
About the author
Relyea has worked in crypto security on the Network Security System code used in Mozilla browsers since 1996. He joined Red Hat in 2006. He is also the co-chair of the OASIS PKCS #11 Technical Committee.
More like this
BackendTLSPolicy expands Gateway API transport security
Can't patch fast enough? Zero trust as a last line of defense
Collaboration In Product Security | Compiler
Keeping Track Of Vulnerabilities With CVEs | Compiler
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds