Part I: Like a Rainbow in the Dark
If you search for distributed tracing, you'll find dozens of articles and blog posts explaining what it is and why it's important. Yet distributed tracing is still not ubiquitous in cloud application environments, especially when compared to its older siblings: logs and metrics. Why is that?
Perhaps the first reason is because it’s fairly new. Despite all the literature, it’s very common to hear: What's distributed tracing? Is it low-level debug logs? What's the real value? There are other common questions that, at first glance, don't seem related to distributed tracing: How can I correlate logs? How do I add AI to my observability platform to alert me when there’s a problem? How can I store millions of metrics collected over months and save them for a rainy day?
While distributed tracing does not provide a direct answer to some of the latter questions, it does unveil the fact that maybe you don’t even need to answer them in the first place!
In this blog series, we will walk together through an Observability Adventure where distributed tracing will emerge as an important step towards understanding and troubleshooting complex distributed systems. Down the road, we will answer common questions and provide some recommendations to get started and achieve effective and maintainable observability from day one.
We will start by transforming the very well-known logging events into something a bit more suited for a distributed system. Then we will focus on adopting best practices to address code instrumentation. We will also discuss how to set up a good performing distributed tracing stack that's able to cover your needs from small applications to large clusters.
To learn more about observability in general, visit here.
The Drama of Distributed Systems
We have all heard (and sometimes agree) that monoliths are bad. So, in the name of scalability, fault-tolerance, maintainability, and even agility, we all took our swords and went hunting monoliths, moving towards the microservice paradigm. Even upper management was pushing for Kubernetes without a clear understanding of its consequences!
The Good Old Days
But after all the hype, a monolith was not that bad for some things, was it? Less repos, no APIs to maintain, teams focused on end-to-end functionalities… those were the days! Having several teams in the same code base was nice. It provided some level of knowledge sharing and the spice of delivery meetings where everything could happen.
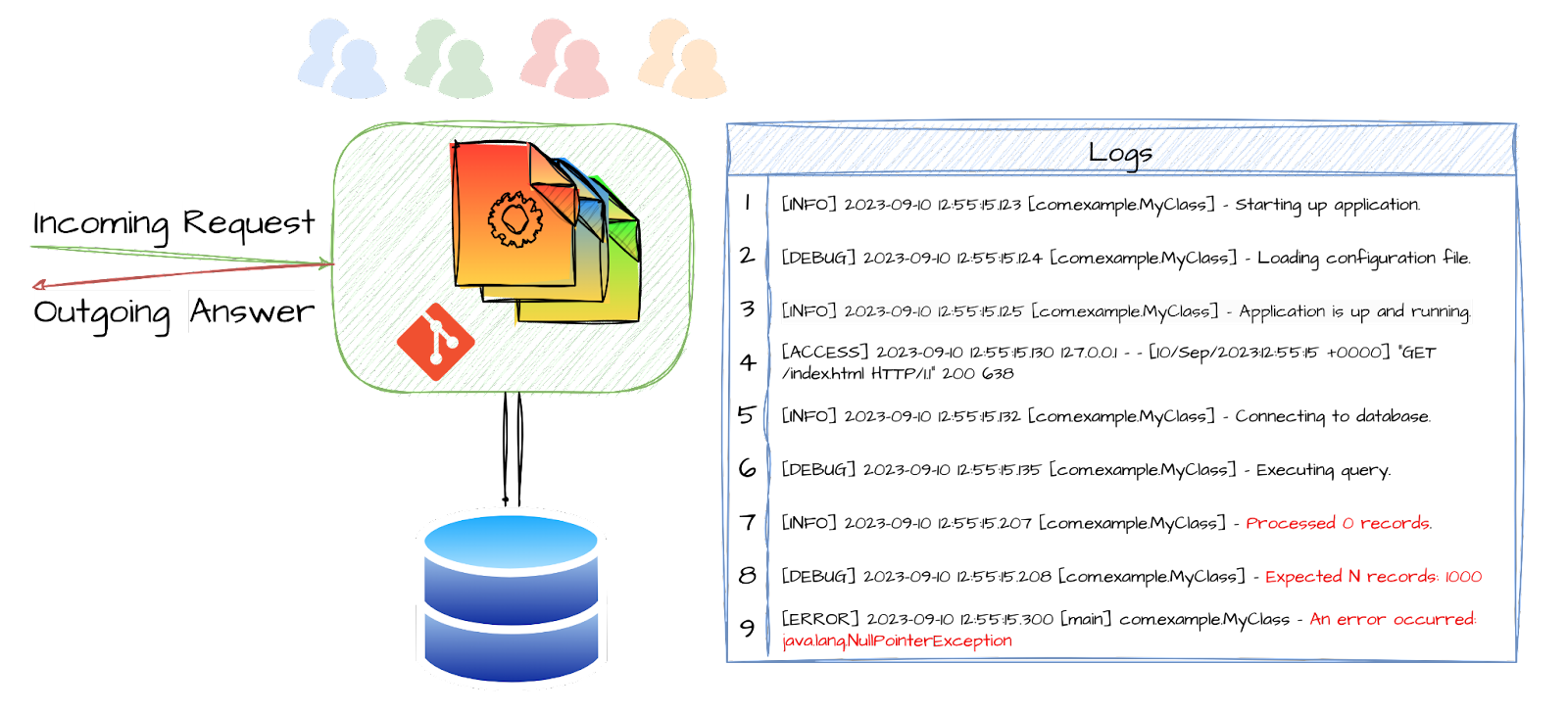
In order to solve an escalation, you could just go into a war room with a couple of senior devs. They knew their code and how to take care of it. They could add/activate some debug logs here and there, and just like that, fixed it! These logs might actually be as rich and complex as you could imagine: timestamps, thread-ids, request-ids, you name it. We had a monolith, but it didn’t mean it wasn’t multithreaded or asynchronous.
In general, we had a good Mean Time to Detect (MTTD), if that was even a concept. The Mean Time to Repair (MTTR) was just a matter of how good our delivery pipeline was because we all know that the difficult part is pointing the finger. Solving the issue is always fun.
Who You Gonna Call?
Today, with the broad adoption of Kubernetes, we need to structure our organizations accordingly to be efficient (or the other way around, according to Conway). Our teams’ setup has changed a lot. Instead of working in back-to-back lines of business, our teams own one or two microservices each. That's very convenient because they know their code, they develop in their favorite language (or even experiment with new ones), and we solve the integrations with resilient APIs. This helps designing a good CI pipeline with small unit and component tests, too.

Well, what they didn't tell us was what the next escalation was going to look like. We’ve lost the ability to get those two brilliant engineers in the war room because each of them own their own microservices and don't even know the programming language of some of the other software pieces involved. Apart from that, the failure is only happening in a small percentage of the thousands of requests your system is processing every second. How can they possibly know what's causing the issue? Spoiler alert: If you create a SRE team, they will end up asking you the exact same question.
After all this frustration, you look on the internet and find the solution to all your problems: a third-party application with AI! Of course, that could be a solution. But maybe there’s a more straightforward one right in front of you.
From Logs to Distributed Traces
When we're born, our first instinct is to cry –a universal signal for our needs. It helps us to achieve lots of things in our early days. As life becomes more complex, crying won't suffice and we are forced to learn to communicate effectively.
Similarly, in programming, our first executable is often a "hello world" which essentially logs a message as a diagnosis of something that just happened. Can we use it for everything? Should we stop there? Logs are very useful but sometimes limited. As complexity grows, we must embrace a richer language.
We already took a great first step. But let’s continue! This journey has just started. Next stop: Span.
Spans
Remember the log with timestamps? That’s very close to the definition of a Span: a structured log representing an operation occurring between a start and an end timestamps. It may be decorated with other attributes and status codes representing how a span resulted.

And how do we name those attributes? Luckily for us, there are some conventions available in the OpenTelemetry standard, so we don’t need to argue about whether the operation result should be named http.status_code or sTaTuS-CodE.HTTP. If you think about it, all distributed systems are very similar: “Service A sends a request to Service B”, “Service X queries the database with this particular request”, and so forth, so there’s a high probability that the attribute you need to add is already contemplated under the OpenTelemetry Semantic Conventions.
In any case, we all know that naming is one of the hardest challenges we face in software engineering, so you can always add custom attributes if the pre-existing ones don’t cover your needs.
But that’s not all. Remember that we love to add debug traces everywhere in the code saying “John Doe was here” or “if we reach this line: brace yourselves”. This is accounted for in distributed tracing by adding events to spans. Events, as defined in this framework, also have convenient timestamps embedded into them. You are free to add as many of them as you need in a span, so fear not – this capability is still there. Of course, the recommendation is to only add those meaningful ones.
Distributed Traces
Great – the path is not looking bad. We have structured our logs. Being able to agree upon a logging structure and content has great value, but this is not solving the distributed issue. Remember that we have a set of services written by different people in different languages. Some of these people are sitting in a room having a hard time to know where the fire is so they can extinguish it.
Taking into account that our application is serving several requests at the same time, we start to dream about connecting all those logs together to see if, by looking at the forest, we can identify the rotten tree. Is it time now for AI? Wait a second, we are just one step away from reaching our third milestone.
Let’s provide a unique identifier to every incoming request and propagate it all the way across our microservices. That’s something we can do regardless of the programming language. By doing so, we can now draw a tracing line (like an arrow with a rope or tracing bullet) and get for the first time a complete view of what happened! Just like that, we have enabled gathering all spans related to a request under the same umbrella. And that umbrella is what we call a Trace.

A Final Touch: The Fireworks of Bonding Spans
While this chronological view of spans being called one after the other is nice, there’s something still missing: Operations can be nested with some sense of precedence and hierarchy. And we just said that spans are our representation of those operations. Distributed tracing is very well aware of this, and that’s why it adds two more concepts to the mix:
- Parent-child relationships: to group spans as sub-operations being part of other high-level ones.
- Span links: to show cause-effect relationships.
These two, added to the timestamps, allow us to produce very informative views that, together with the appropriate visualization tool, will be our most effective weapon to check where the issue is, together with its overall transaction context.

We have walked a long way. We started with a generic, not-very-helpful “Database error” type log. Now we have all the context to figure out what exactly happened since we received a request until the error happened. In between, all relevant events and communications between services are traced (or logged). But that’s not all. If that was not enough, we now have the ability to play “spot the difference” between a healthy distributed trace and a problematic one. When we cannot see where the problem is, distributed tracing shines like a rainbow in the dark.
By the way, if you are curious about what a span looks like, there are very good examples of spans and their relationships in the OpenTelemetry concepts page.
The Challenges of Distributed Tracing
So, if this is all about throwing some educated printf’s here and there, why would anyone even care about complex AI/ML models with tons of Gb of data to maintain? There are a few reasons, and that is why this article aims to be the first of a blog series where we can explore how to demystify the details of these reasonable fears. We will barely enumerate them now, but stay tuned for dedicated deep dives into the following subjects. Of course, we will outline some directions if you can’t wait to read the next episode.

Instrumentation
Distributed tracing may seem difficult to implement. It requires instrumenting your code to add trace information to each request. It’s not always easy to propagate context, especially for legacy applications that have not been done taking this into account. Instrumentation can ultimately entail large refactors, which can be time-consuming and error-prone.
The good news is that you don’t need to do all of it at once. Automatic instrumentation with OpenTelemetry and service mesh with out-of-the-box tracing capabilities are good starters to taste the added value of tracing without touching any line of your business logic.
Another common organizational pattern is to create a small tiger team formed by individuals from different squads. They will agree to instrument the bare minimum code to fix the most painful issue you have today. By the way, remember that the code language is not important here, because there’s a cross-language standard. It will not only solve issues but help you break silos.
Performance
Observability instrumentation is sometimes considered a source of performance loss to certain applications. This is because, when instrumenting the code, additional objects (spans) need to be created and data needs to be reported, which is additional work to be done. There are many strategies to address this. For instance, you don’t need to reinvent the wheel; there are already well suited SDKs waiting for you to just use them. You can also decide to not collect all traces by sampling and alleviate the signaling storm with batch processing. These features are very easy to configure.
Frameworks
There are a number of different distributed tracing frameworks available, which can make it difficult to choose the right one for your needs. Some applications are instrumented using OpenTracing as their instrumentation API with Jaeger SDK, while others are using Zipkin.
Guess what? The OpenTelemetry project comes to help. It provides the SDKs for all the important programming languages, defines the APIs to communicate between services, and even provides a protocol: the OpenTelemetry Protocol (OTLP). After all this work in the community, there’s really one good choice: the OpenTelemetry standard. Apart from that, the OpenTelemetry collector is able to receive and export data in all major distributed tracing frameworks, so it can really help when mixing different projects or while transitioning towards standardization inside your observability stack.
Complex Observability Architecture
With logs, sometimes even a console is enough. For more elaborated observability setups, we need to produce, collect, transform, and store the data so it can be analyzed later. The answer to this issue is very similar to the instrumentation one: Start small and take it from there. There are monolithic, short-lived solutions that can be up and running in seconds.
How to Get Started with Distributed Tracing and Benefit from Day One
If you made it this far, you might be considering distributed tracing to improve your observability arsenal. While we will elaborate on the following statements, these recommendations will help get you started:
- Start with a proof of concept. Don't try to instrument all your lines of business from the beginning. Instead, start with one service and keep it high-level.
- Try to collect traces from all of your services involved in the overall transaction. This will give you a complete view of your distributed system.
- Use a standard tracing API and framework: OpenTelemetry. This will make it easier to instrument. Be prepared to switch tracing providers in the future in case you need to.
- Start by storing your traces in a volatile and easy-to-configure backend such as Jaeger all-in-one or Tempo monolithic deployments.
- Start with a simple and open visualization framework like Jaeger or Grafana.
- A service mesh like istio provides tracing up to some level. Of course, the mesh cannot carry the context through your code, but it’s a very good start to understand your service architecture. You can also check kiali out (the observability console for istio).
- Culture eats strategy for breakfast. Form a small cross-service tiger team and let them spread the word.
- Have you ever dreamt of an Application Monitoring Tool (APM)? Distributed tracing will provide you automatically with Request, Error and Duration (RED) metrics out of the tracing box without the need of using other instrumentation frameworks, so you can observe latencies and request and error rates.
Conclusion
Everybody knows what a log and a metric is, perhaps because logs are the first thing we learn and metrics sometimes come as a requirement. Distributed tracing is a powerful tool for improving the observability of your distributed systems. If you're looking for a way to troubleshoot problems in complex cloud systems, identify bottlenecks, and improve the performance of your applications, then distributed tracing is worth considering.
When adding this technology to your observability toolbox, you will be ready to:
- Understand your service topology
- Depict the end-to-end path that a particular request travels through your system
- Bring context to an error
- Compare traces between successful and unsuccessful queries
- Track time consumed by single operations in a large and complicated system
- Clearly identify which operation is failing with low level detail
- Automatically produce metrics out of traces
- Adopt standards across different programming languages and onboard your project into the OpenTelemetry framework
- Breaking silos through collaboration between teams
- Have an out-of-the-box APM
Thanks for reading, and stay tuned for a deep dive in the concepts previously discussed!
Further reading
- OpenShift distributed tracing release notes
- Tempo documentation
- OpenTelemetry collector documentation
- redhat.com/observability
- Blog: How to deploy the new Grafana Tempo operator on OpenShift | Red Hat Developer
- Blog: Simplify managing Grafana Tempo instances in Kubernetes with the Tempo Operator
- Blog: Observability across OpenShift cluster boundaries with Distributed Data Collection
- Blog: Using OpenTelemetry and Jaeger with Your Own Services/Application
- Blog: What is OpenTelemetry?
- Blog: What is Observability?
About the author

Jose is a Senior Product Manager at Red Hat OpenShift, with a focus on Observability and Sustainability. His work is deeply related to manage the OpenTelemetry, distributed tracing and power monitoring products in Red Hat OpenShift.
His expertise has been built from previous gigs as a Software Architect, Tech Lead and Product Owner in the telecommunications industry, all the way from the software programming trenches where agile ways of working, a sound CI platform, best testing practices with observability at the center have presented themselves as the main principles that drive every modern successful project.
With a heavy scientific background on physics and a PhD in Computational Materials Engineering, curiousity, openness and a pragmatic view are always expected. Beyond the boardroom, he is a C++ enthusiast and a creative force, contributing symphonic and electronic touches as a keyboardist in metal bands, when he is not playing videogames or lowering lap times at his simracing cockpit.
More like this
Strengthening the enterprise foundation: Red Hat and Oracle’s expanding collaboration
Integrating Red Hat Lightspeed with CrowdStrike for enhanced malware detection coverage
Crack the Cloud_Open | Command Line Heroes
Edge computing covered and diced | Technically Speaking
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds