
OpenShift is a powerful and complex product. With hundreds of possible goals a user could accomplish across multiple interfaces, how do we know where to prioritize our work? What tasks are most important to our users? Our team wanted to use an empirical approach that would let us generalize our prioritizations to all OpenShift users.
Top Tasks is a research methodology that was created specifically to find users’ greatest priorities in a product. When Gerry McGovern developed the approach, he wanted to find a data-driven way to help his clients focus on what matters most and safely deprioritize less important parts of the interface. There are a lot of little considerations, but these are the four main steps in the process:
- Gather user tasks.
- Come up with a shortlist of these tasks.
- Find users to vote.
- Visualize the data.
Through these steps, we focused our understanding from a set of over 100 possible tasks with no priority to a set of 2 to 3 critical top tasks and 5 to 6 additional important tasks.
We used this process to find our users’ top tasks in the command line interface (CLI) and the web console (UI). In addition to the top tasks, we measured each task’s difficulty and some background characteristics of each respondent.
Process
1: Gather user tasks.
Steps 1 and 2 are the qualitative phases of top tasks research. We used these to explore the problem space so that we could be sure we were going to measure the right tasks. We relied on help from OpenShift users within Red Hat to help generate this list.
We sent a survey out to all of Red Hat for subject matter experts. Our teammates answered the call with about 250 Red Hatters generating 416 possible tasks in OpenShift. This survey was open-ended, with some guidance around the kinds of tasks we were looking for. We wanted to find discrete, pragmatic goals in the interface like “start a pod,” which is somewhere between granularities of “create a robust hybrid cloud platform” (too lofty) and “click the start button” (too narrow).
2: Come up with a shortlist of these tasks.
With 416 tasks, we needed to streamline this to a “short” list of tasks. This was a qualitative and manual process of going line-by-line to assess, compare, and contrast. After the list was around 150 tasks, 16 diligent Red Hat OpenShift users marked each item with at least one of the following labels:
- Duplicate
- Poorly worded
- Miscellaneous issue
- Good to go
With the final survey check and a couple meetings to ensure the validity of the tasks, we had the (relatively) short list of 124 tasks.
3: Find users to vote
For our users to vote, we implemented the 124 tasks into a Qualtrics survey. Many OpenShift users and customers voted on their five most important tasks in the CLI (whether that meant the most common OpenShift CLI, oco, or the newer developer-focused command line, odo) and the web console. Ultimately, we got responses for about 375 top tasks votes in the CLI and web console (UI).
Most of our respondents came from internal customer lists. Another major source were respondents from the OpenShift blog post. However, we also tried as many avenues as we could think of that were less traditional, from the OpenShift subreddit (on reddit.com) to Kubernetes and OpenShift Slack groups.
Our most typical respondent was a system administrator with an intermediate-advanced level of expertise in OpenShift using version 3.11. Respondents did represent a wide variety of users. In expertise, we removed those responses that reported no OpenShift experience and then had everything from beginners to experts. In the role category, we mostly had system administrators, but we also found large proportions of developers, SREs, cloud architects, application operators, and others (VP, project managers, and others). Most respondents noted their bulk of experience was with version 3.11, followed by respondents indicating 4.2, but some experiences stretched back to 3.7 or earlier.
4: Visualize the data
After all the effort, we found our top tasks for both the CLI and the UI. We used a number of open source tools to analyze and visualize the data (RStudio and ggplot). It became clear that a few tasks were far more critical than the vast majority of possible tasks one can complete in OpenShift.
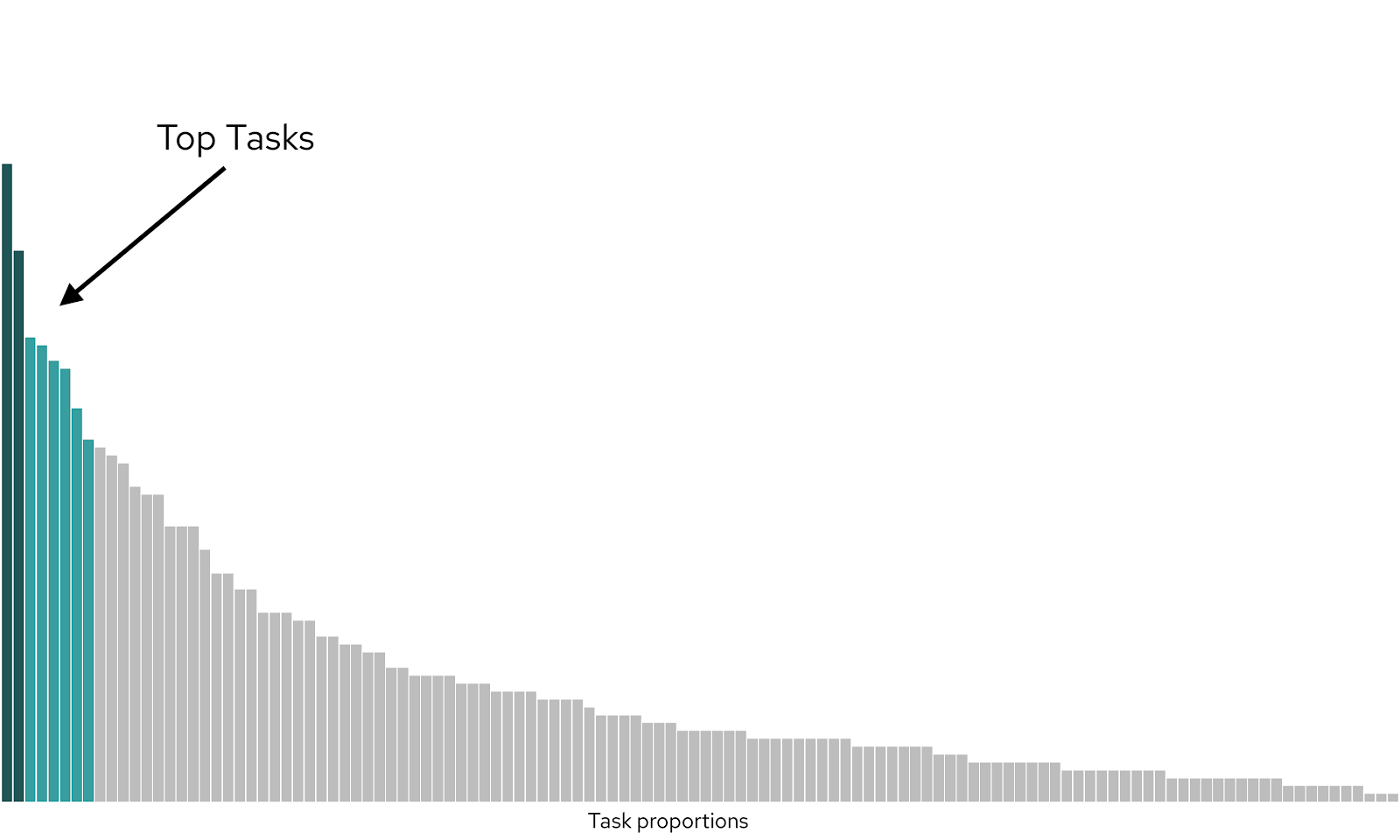
The UXD team at Red Hat has used this information to clarify how we are developing new features right now. We’re also working with our documentation team to understand how this newly found prioritization can help determine where to develop content.
Next steps
Now that we know what tasks are critical to our users, we need to learn about why our users typically do these tasks and conduct usability testing to ensure we fix any usability issues. If you took the previous top tasks survey and signed up for our research participation pool, you may be invited to a follow up study. If you haven’t signed up for our research participation pool, please sign up here, and you’ll be invited to future research opportunities that match your background (possibly including our top tasks follow up).
Many thanks to all OpenShift users who helped give their input on this project. Your responses have a direct impact on OpenShift, and we greatly value your participation.
執筆者紹介

類似検索
チャンネル別に見る

自動化
テクノロジー、チームおよび環境に関する IT 自動化の最新情報

AI (人工知能)
お客様が AI ワークロードをどこでも自由に実行することを可能にするプラットフォームについてのアップデート

オープン・ハイブリッドクラウド
ハイブリッドクラウドで柔軟に未来を築く方法をご確認ください。

セキュリティ
環境やテクノロジー全体に及ぶリスクを軽減する方法に関する最新情報

エッジコンピューティング
エッジでの運用を単純化するプラットフォームのアップデート

インフラストラクチャ
世界有数のエンタープライズ向け Linux プラットフォームの最新情報

アプリケーション
アプリケーションの最も困難な課題に対する Red Hat ソリューションの詳細

オリジナル番組
エンタープライズ向けテクノロジーのメーカーやリーダーによるストーリー
製品
ツール
試用、購入、販売
コミュニケーション
Red Hat について
エンタープライズ・オープンソース・ソリューションのプロバイダーとして世界をリードする Red Hat は、Linux、クラウド、コンテナ、Kubernetes などのテクノロジーを提供しています。Red Hat は強化されたソリューションを提供し、コアデータセンターからネットワークエッジまで、企業が複数のプラットフォームおよび環境間で容易に運用できるようにしています。
言語を選択してください
Red Hat legal and privacy links
- Red Hat について
- 採用情報
- イベント
- 各国のオフィス
- Red Hat へのお問い合わせ
- Red Hat ブログ
- ダイバーシティ、エクイティ、およびインクルージョン
- Cool Stuff Store
- Red Hat Summit